A Type System for Knowledge Graph Entities
Author: Oscar Li, Software Engineering Lead
Product: Knowledge Graph
Blog Date: January 2021
Yext's Knowledge Graph stores all the public facts about our customers' brands. Whether it be the date of a Ben & Jerry's Free Cone Day or the address of a Qdoba restaurant, these facts are used to answer consumer questions, power landing pages, and manage listings across the internet.
Within the Knowledge Graph, facts are expressed as entity field values. Here, an entity can be pretty much anything under a customer's brand (e.g. a location). An entity itself has multiple fields (e.g. a "Business Name" field), each of which stores a corresponding value.
We've defined a type system that assigns a type to each field. A field's type dictates the field's structure and validation semantics. In this blog post, we're going to take a deeper look at this type system and the expressiveness that types bring to the Knowledge Graph.
Primitive Types
First, we have a set of primitive types. Similar to the role that primitive data types play in programming languages, these primitive types serve as the fundamental building blocks in our type system:
- String - A string (e.g. "foo")
- Boolean - A boolean (e.g. true)
- Integer - An integer (e.g. 1)
- Decimal - A decimal (e.g. 1.2)
- Option - An enumeration of possible values for a field
- Date - A date (e.g. 1/1/2020)
- Rich Text - Text with additional formatting options such as bold or italicized text (e.g. Hello world)
- List - A list of values that are all of the same type
- Struct - A set of properties where each property is defined by a unique name and a type
Using the List and Struct types, we can create nested types to model more complex data. What if we wanted to model a "Blog Post" type? We can do so by using a Struct with a Rich Text property for the the post content, a String property for the author, and a Date property for the date published. We refer to these property types as subtypes.

We also enable our customers to use primitive types to create their own custom types. In turn, customers can use their custom types to create their own custom fields (or even more custom types).
Data Validation
Each primitive type may also contain additional metadata that provides field validation semantics. For example, a Date type may specify a minimum and maximum date value for the field.
Whenever a user updates an entity - whether that be through web application, API, or mobile application - an update request is made to an entity data backend service responsible for managing the field values associated with each entity.
The update request specifies a field and a value. The entity data service retrieves the type associated with the specified field and checks that the specified value conforms to that type. If the specified value does not conform to the type, then the entity data service rejects the update.
Let's use the "Date Published" subtype described above as an example. Let's say that we don't want any blog posts published before 2020 so we specify a min_value in the Date type:
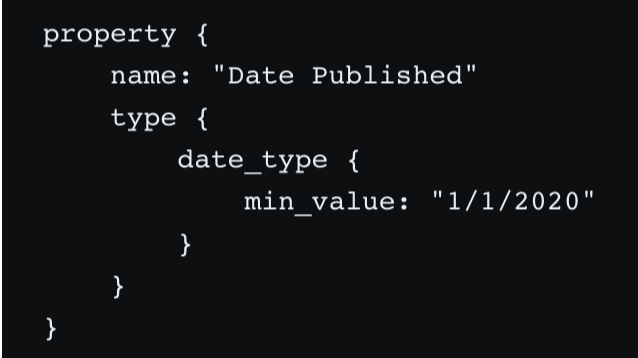
If someone tries to set the "Date Published" value to a date before 1/1/2020, the update will get rejected. Similary, if someone tries to set the "Date Published" to "foo", the update will get rejected because "foo" is not a Date.
Reusable UI Components
Types also instruct our UIs on how to display fields. We've built a generic UI component for each primitive type.
For String type fields, we display a text input box for users edit the field.

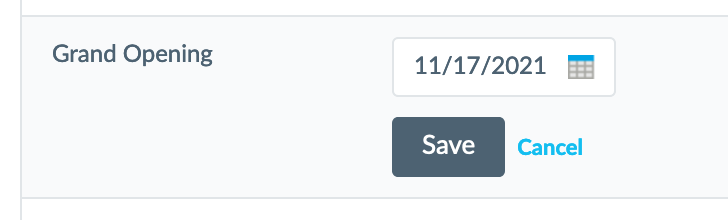
For Date type fields, we display a calendar to select a date from.
For Rich Text type fields, we display a rich text editor.

And you can probably figure out how we display the "Blog Post" type field.
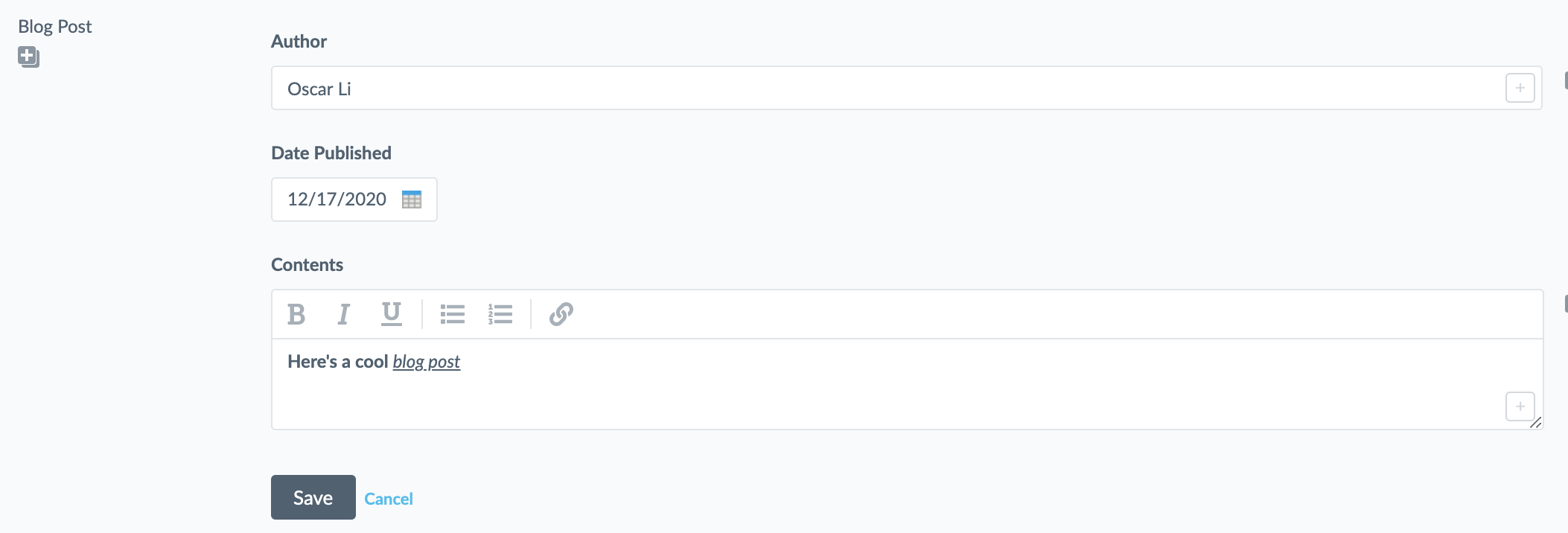
Just like how any type is a composition of primitive types, any field UI component is a composition of primitive UI components.
Conclusion
Our type system serves as the foundation of the Knowledge Graph by dictating the structure, validation, and display of fields. The type system guarantees the consistency and correctness of any field value retrieved from the Knowledge Graph. This makes it easier for our engineers to reason about code that handles particular fields, for our customers to manage their entity data, and for our publishers to trust the quality of our data.