Behind the Scenes of NER Nightly Retrains
Authors: Deeksha Reddy, Associate Data Scientist
Product: Answers
Blog Date: August 2021
What is NER?
One of the most important elements behind well-performing site search is NER: Named Entity Recognition. NER is an AI technique that identifies key information in text. At Yext, NER is used to identify all the different entity types (i.e. products, people, places, dates, customer service problems) in a given Yext Answers query. The performance of NER is crucial because based on our NER model's predictions, we directly search the Yext Knowledge Graph to find the information the query was referencing and serve the most relevant search results.
Let's take a look at an example:
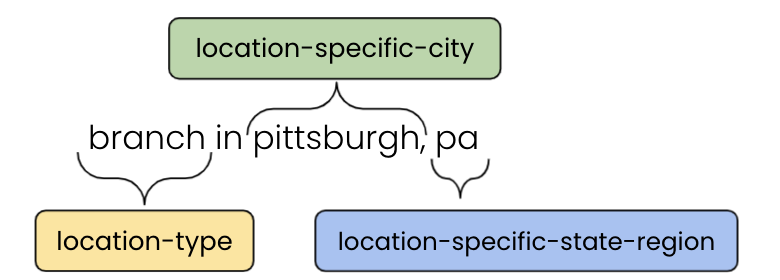
If someone were to search for "branch in pittsburgh, pa", our NER model would label "branch" as a "location-type", "pittsburgh" as a "location-specific-city", and "pa" as a "location-specific-state-region". This then signals for us to search the client's Knowledge Graph for store locations in Pittsburgh and then output the appropriate store location results in/closest to Pittsburgh to the user.
What does it mean to train a model?
Training a model consists of providing a machine learning algorithm with data, to learn and recognize patterns in that specific dataset. Then, when we provide the trained model with new data, it can identify those learned patterns and output smarter and more accurate predictions.
Why do we need to retrain models?
If our model is performing well, why do we need to retrain it? The simple answer to this question is — because things are constantly changing! At Yext, we are launching new AI Search experiences all the time and that means there is new data and context that our model can learn patterns from.
What does an NER model retrain look like at Yext?
1. Collecting historical Answers queries as data for our model.
A supervised machine learning algorithm is only as good as the data you train it on. So it makes sense that the first step in our NER model retrain process is to get this data. We get our training data from a couple different places.
First, we get data directly from our clients' end-users.
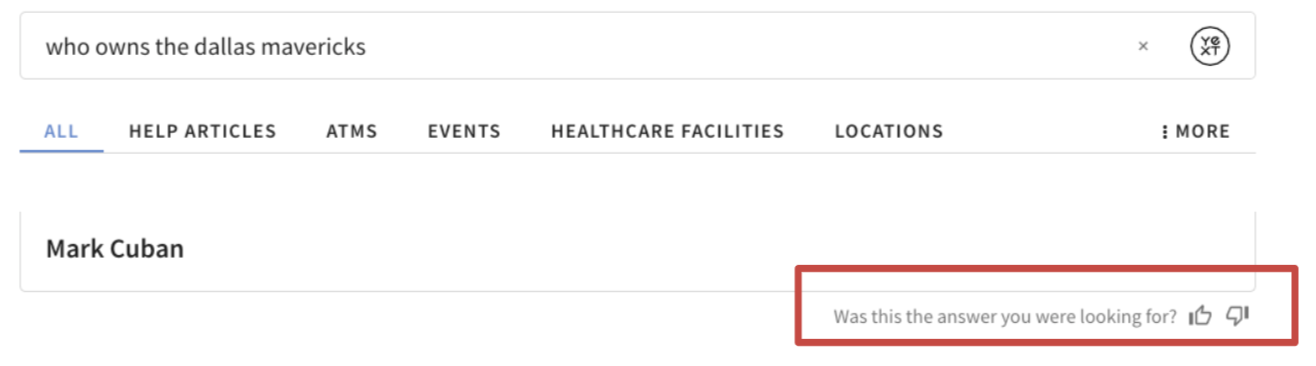
At the bottom of some of our search queries we have a thumbs up/thumbs down option. We collect all of the bad results and make sure we include those data points in our next retrain so the model doesn't make the same mistake again.
We also sample data from newer Answers experiences as well as existing experiences since queries change over seasons and years. For example, in the summer months people are less likely to search for Christmas trees than in the winter, so we want to make sure our training set captures seasonality as well as old and new!
2. Human annotators label entities in each query with the appropriate NER labels.
We have a team of dedicated human annotators that go through and label each query in our dataset. Our annotators label thousands of data points across all of our models every single week, and are a crucial part of our retraining process.
3. Clean & filter labeled data.
After our queries are labeled, we have to make sure we clean the data up. This involves 3 steps. First, we remove all queries where annotators have labeled anything as "unsure". We want only confidently labeled data in our training dataset. We then remove all queries that were labeled "corrupt". This includes queries with profanity and incomprehensible or irrelevant queries. Lastly, we assign each query to at least two annotators. If there are conflicting labels for a particular query, we make sure to remove it from the dataset.
4. Format data for BERT with Wordpiece Tokenization.
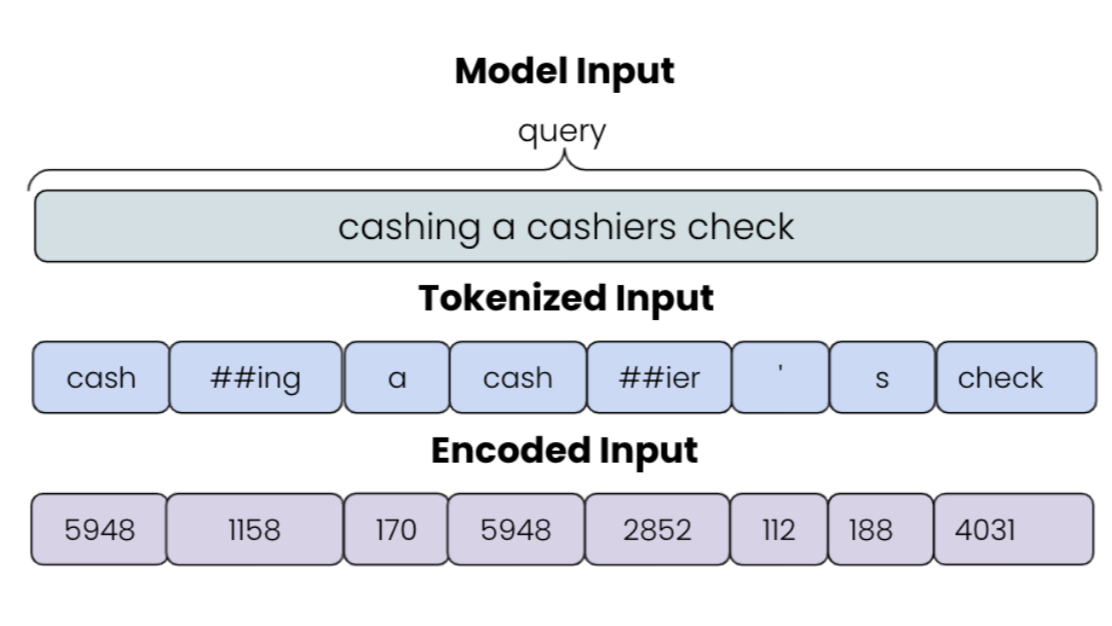
Now that we have our cleaned data, we need to format it in a way that our BERT model for NER understands it. BERT is a powerful neural network based model developed by Google used for a variety of natural language processing tasks. To use BERT for NER, we need to format our input using wordpiece tokenization. Wordpiece tokenization helps the model process unknown words by breaking them down into subword units.
In this example you can see how tokenization splits aparts words like cashing and cashier into the subword "cash" and then -ing and -ier. This is efficient because it allows us to keep the model inputs smaller but still allow the model to learn new content. After a query goes through tokenization, we also have to make sure it is encoded, since ML models only understand numbers not text. These numbers come from an extensive vocabulary file that maps each token to an id. A similar mapping process occurs for all the corresponding entity labels for each query and that serves as our encoded output, which is also passed into the model.
5. Train-Test-Split.
After we have all of our data in the right format, we can then pass it into our model and finally get it trained! In this step, we need to split the data into a 90% training set and a 10% testing set. The training set is used by the model to learn patterns, while the test set is data that is put aside and used to test the performance of the model. Because we know the correct predictions of the data in the test set, we can feed our model the test set inputs and compare the model's predictions with the correct predictions.
When we run the training script we show the model our training data 25 times. Each time, BERT's hundreds of thousands of parameters are fine-tuned in an effort to optimally fit the model to our data. So there is quite a lot of computation going on behind the scenes. After every one of these iterations we use the test set we had put aside earlier to calculate model performance. Ultimately, we save the model file from the best performing iteration of that particular retrain. 2.
6. Evaluating the Model.
We keep talking about performance but what exactly are we measuring? Typically we think of accuracy when evaluating performance. Accuracy is just the number of predictions the model got correct over the total number of predictions made. This could be good, but let's think about a situation such as a doctor giving patients diabetes diagnoses. In America, 1 in 10 people have diabetes, so a doctor who just blindly tells everyone they do not have diabetes will still be 90% accurate. This is why accuracy can become a deceiving metric in some situations.
Similarly, although not as risky, we also want to make sure we are minimizing these false positives and false negatives for NER. An example of a false positive in NER is if we label a person entity as a place. An example of a false negative in NER is if we completely miss labeling a person entity as a person, so we don't identify an entity type that we should have identified. To account for these, we use a performance metric called F1. It is the harmonic mean of precision and recall, which are measures used to evaluate the rate of false positives and false negatives when we run the model through our test set. Since we run the model through the test set after every one of our 25 iterations, we are really looking for the iteration with the best F1 score and we save the model at that iteration.
After further testing to verify a model retrain's performance, we complete the process by deploying our retrain to production.
This process of retraining NER is repeated every single night at Yext. We log each retrain's performance and carefully monitor model performance in production so that we can regularly deploy the latest retrains to production and minimize any possibility of model degradation. We believe that consistent and proactive model retraining is critical in model upkeep and are actively working to expand our retraining process to every model we use behind Yext Answers and across the company as a whole.