BERT: Strengths and Weaknesses
Authors:
Allison Rossetto, Data Scientist
Pierce Stegman, Data Scientist
Product: Answers
Blog Date: January 2022

BERT (Bidirectional Encoder Representations from Transformers), and related transformers, have had a huge impact on the field of Natural Language Processing (NLP). At Yext, BERT is one of the main underpinnings of our Answers platform, particularly as it relates to semantic search (we'll touch on this in a bit). For quite a while, its been a "gray box" because its inner workings havent been well understood. This is common in the field of machine learning, where the community doesnt entirely understand how machine learning models work. However, the models perform so well that many are willing to accept the risks of using a poorly understood tool. As we build more complex NLP tasks, we need to understand the strengths and weaknesses of our methods in order to make better business and engineering decisions. This blog post will discuss some recent research on how and why BERT works, including its strengths and weaknesses.
Before we can talk about the research into the mysterious internal workings of BERT, we need to review the architecture. BERT is based on the transformer architecture. As the name implies, a transformer is designed to transform data. For example, translation software could use a transformer to transform an English sentence into its equivalent German sentence. As such, transformers have become popular in the field of machine translation.
To accomplish this, the transformer architecture has two main parts: an encoder and a decoder. The encoder is designed to process the input and distill it down to its meaning (independent of the language). For example, lets say we assign the ID "12" to "the phrase used to greet someone in the morning". The encoder would accept "Good morning" as input, then it would output "12." The decoder would then know that "12" encodes the phrase thats used to greet someone in the morning, and it would output "Guten Morgen" (German for "Good morning." In practice, the encoder outputs more than a single ID, such as "12." Instead, it outputs hundreds of decimal point numbers which encode the meaning of the input. The decoder then decodes all of these numbers into the second language.
It turns out that these numbers output by the encoder are useful for more than just machine translation. Within the context of our Answers platform, BERT helps us translate queries and phrases into values that can be more easily compared, contrasted, or otherwise analyzed. For example, it can be used to detect if two queries are similar. Given the queries "I want to buy a car that seats 8" and "Where to get a new minivan," it may be difficult for a computer to realize they are similar, as on paper, they share very few words. However, when passed through a series of encoders, they are assigned similar numbers. For example, the encoder output for the first query might be 768 values such as [0.89, 0.20, 0.10, 0.71, …] and the encoder output for the second query might be 768 separate (but similar) values such as [0.87, 0.21, 0.12, 0.68, …]. Once again, in practice, its slightly more complicated. The encoder will actually output many sets of 768 numbers, such as those mentioned above, and we combine them together via summation or averaging. These combined outputs are called embeddings or embedding vectors. While its hard to compare queries as a series of words, its easy to compare numbers, and the computer can detect that these outputs are very similar based on their embeddings. We dont need the decoder part of the transformer to accomplish our goal of detecting similar queries, so we remove it. This is what BERT is — a series of encoder layers.
Figure 2 shows the architecture of an example vanilla transformer, while Figure 3 shows an example BERT architecture.
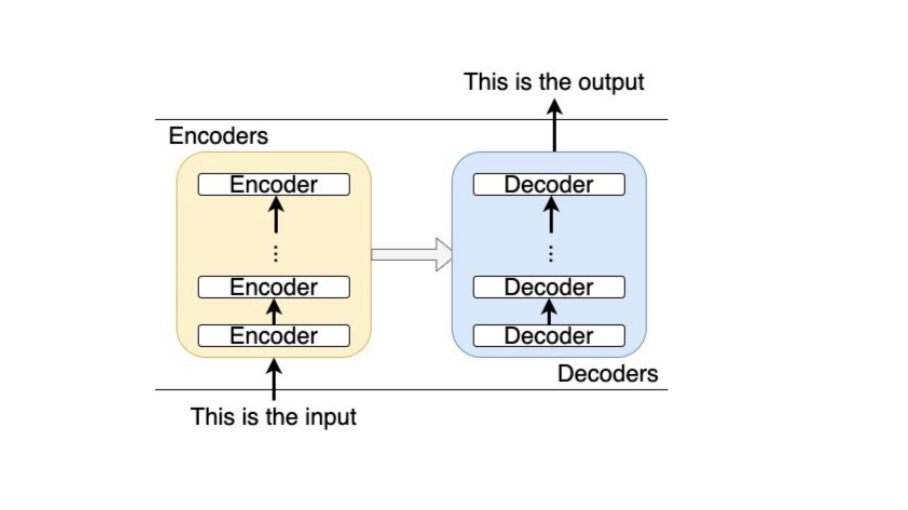
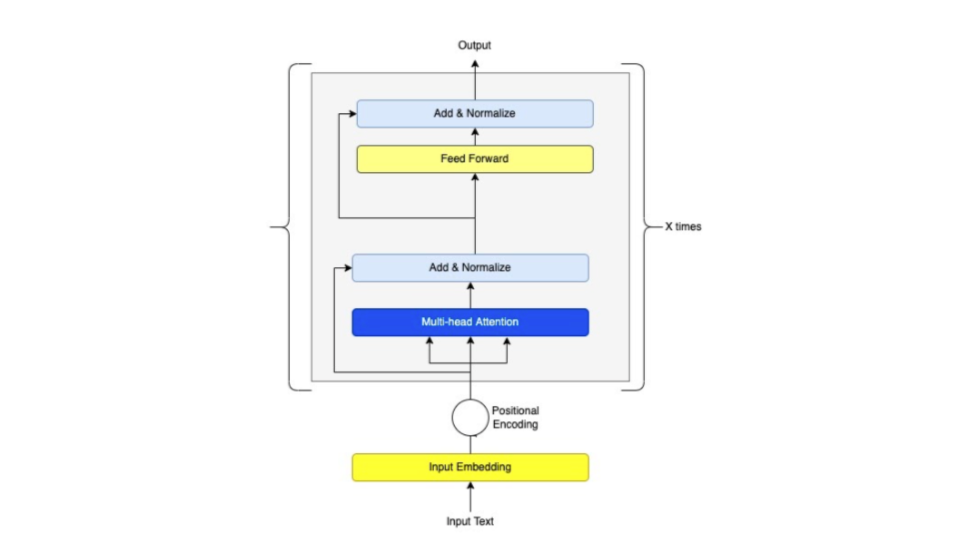
It is important to know that encoders don't read text sequentially like people do, they actually read in the entire sequence of words at the same time. They are considered "bidirectional," so they work with sequences regardless of whether they are read left to right or right to left. This also lets the model get information about words based on context (i.e. the words around a specific word).
One other really key component of transformers that we need to understand is attention. Attention is exactly what it sounds like: it lets the model pay attention to words around other words. This allows the model to determine how each word is being used in context, as the meaning of a word can change depending on the sentence. Figure 4 shows an example relationship between a single word in an example sentence and the rest of the sentence. In Figure 4, we can see that BERT is using the words "how" and "helps" when determining how the word "attention" is being used. This process repeats multiple times, as the model explores many possible relationships between the words. This can be seen in Figure 5, which shows a subset of all the relationships the model created.
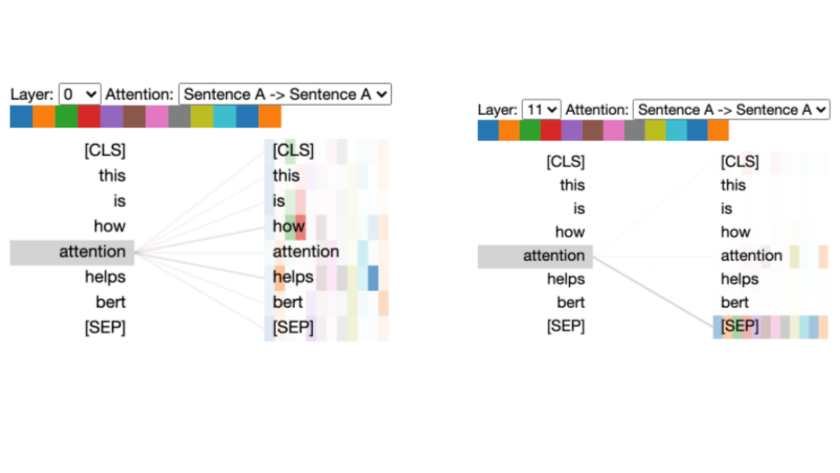
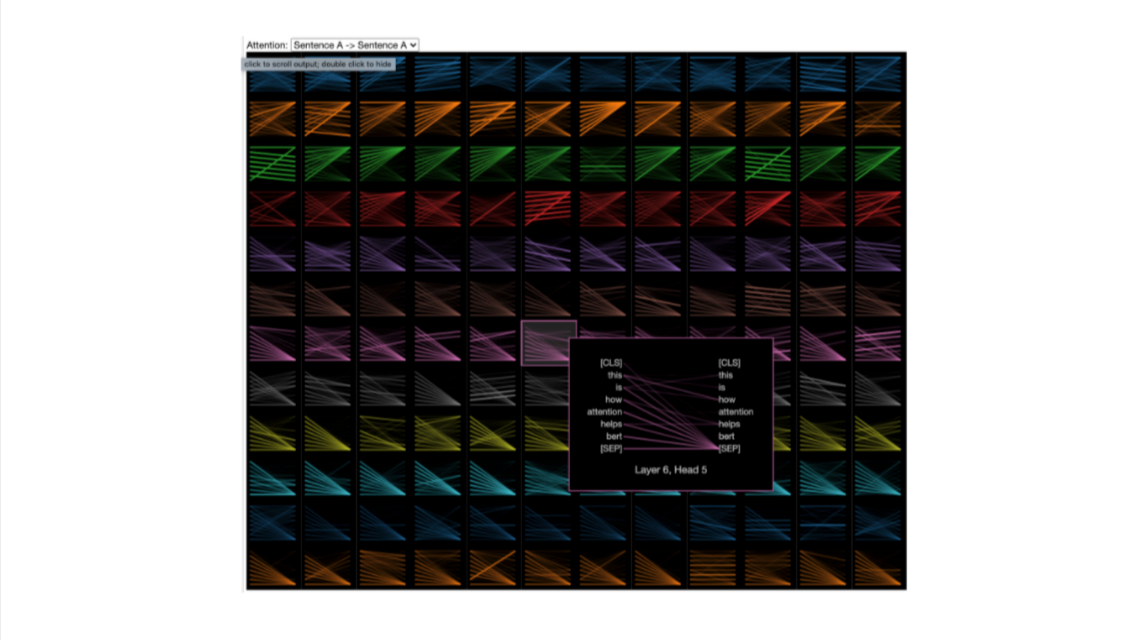
At Yext, were using BERT for semantic search. Semantic search uses embeddings to compare results to queries, rather than doing simple word matching. As we build more complex search experiences and try to improve the results of our searches, we need to better understand what exactly BERT is learning, and what context around words it is embedding in the vectors it outputs. This is a complex area that has traditionally been ignored since most of the time the outputs from BERT and other transformers were "good enough" for their use cases. But as time has gone on, people have been interested in investigating why we get the results we get and what it is that BERT learns. We already know that BERT isnt reading or understanding language in the same way we are, but what exactly is it doing? We can track some relationships between tokens, but can we dig deeper and really understand what is going on?
This leads us to a few questions that we can ask that outline an area of research for how BERT actually works:
- Does BERT follow any recognizable relationship patterns? If it does, what are they?
- If there are patterns, are these different over different attention heads? How important are they for different tasks? (BERT checks multiple possible word relationships in parallel, and each parallel task that is looking for relationships is called an attention head.)
- What is it that BERT is learning? Can we identify the parts of language and the context that is being embedded and used by BERT for different tasks?
The first question is actually fairly easy to answer. Research has found that there are five distinct attention patterns seen in BERT. These patterns are defined as:
- Vertical: mainly corresponds to attention to special BERT tokens [CLS] and [SEP] which serve as delimiters between individual chunks of BERTs inputs
- Diagonal: formed by the attention to the previous/following tokens
- Vertical+Diagonal: a mix of the previous two types
- Block: intra-sentence attention for the tasks with two distinct sentences (such as, for example, RTE or MRPC)
- Heterogeneous: highly variable depending on the specific input and cannot be characterized by a distinct structure and can contain other patterns not seen in the other categories
Figure 6 shows an example of each of these patterns listed above. We can see that these all look distinctly different!

These patterns can also be looked at in terms of task. The data sets used for these tests were a subset from the GLUE task set, which includes a diverse set of natural language examples. As the data set is so diverse, it serves as a good basis for exploring how BERT behaves. Figure 7 shows how consistently these patterns are repeated across different heads and tasks. This consistency indicates that the pattern types don't change by task, and they all have specific parts to play.
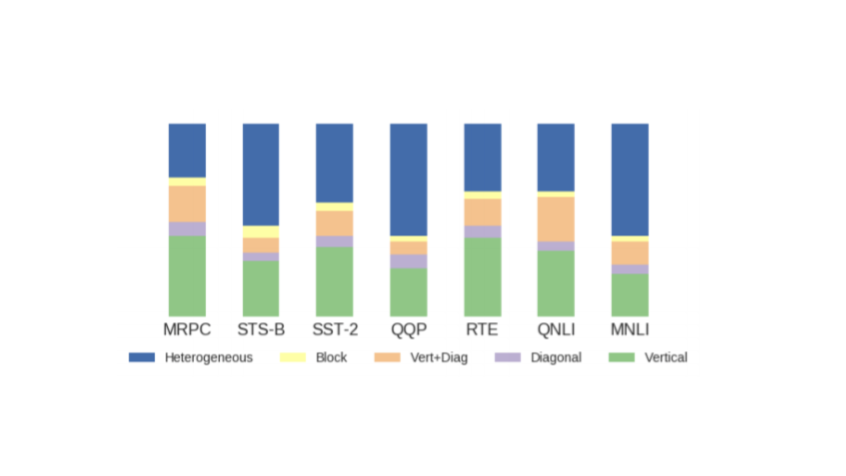
Now that we know what patterns exist and how often we see them, we can start digging deeper. What is actually happening in each of these layers?
The first thing we can do is consider where the biggest changes in the models actually occur. Figure 8 shows that generally, regardless of task, we can expect the biggest changes in the BERT model to happen in the last two layers. This leads to the conclusion that early layers are responsible for fundamental and low level information while the last two layers predominantly encode task specific information that are responsible for gains in scoring. This is further supported by showing that BERT models trained starting with weights created randomly from a normal distribution do consistently worse than models that use pre-training followed by fine-tuning.
Pre-training refers to when a model like BERT is first trained on a general and simple task before being trained again (fine-tuned) on a more complex task. It's important to understand here that, for all of the tasks, the pre-training is the same. Combining this with the fact we can observe the early layers have less change during fine tuning, we can conclude that pre-trained BERT contains some linguistic knowledge that is preserved and passed on during fine tuning.

Now that we know what is happening where, we need to think about the patterns we discovered: what do these patterns mean? Figure 9 shows that the vertical attention pattern is associated predominantly, if not exclusively, with attention to [CLS] and [SEP] tokens. The [CLS] is the internal classification token for BERT, while the [SEP] token is the separator token.

There's a similar pattern when looking at token-to-token attention patterns as seen in Figure 10. The [SEP] token becomes particularly important for most tasks where there are multiple sentences involved, regardless of what particular kind of task they are. This is an issue because that means in these cases BERT isn't necessarily making decisions based on semantics or language rules but mostly based on one of the end-of-sentence examples it's seen. For some tasks this might never be a problem, but there are many tasks where semantics, meaning, and even grammar are important. In these cases, we can think of BERT as "guessing" at the correct answers by looking at the patterns between the sentences rather than actually using the sentences themselves to come to an answer.
Currently, we have some ways to work around this in practical settings, such as with customer-specific customizations and other post-processing steps like search re-ranking (which can rearrange results to show what is currently the best answer based on interaction). However, it is still important to fully understand what BERT can and can't currently do because it gives our customers better outcomes by helping us understand what we need to do!
Further experimentation was also done where certain attention heads and attention patterns were disabled, it was found that certain heads and patterns can be detrimental to BERTs ability to learn certain tasks. This suggests that model pruning, the process of removing some connections in a model, and other changes to architecture design may be beneficial to improving BERT results [Kovaleva et al., 2021].

There is no magic bullet in NLP — no system that will magically understand everything. BERT has strengths and weaknesses like everything else. It's important that we understand those weaknesses so we're better able to address them and make important decisions and improvements. Here at Yext, we strive for perfect answers everywhere. Understanding BERT's limitations is just one of the steps we are taking towards getting there!

Papers referenced:
Kovaleva, O., Romanov, A., Rogers, A., & Rumshisky, A. (2019). Revealing the dark secrets of BERT. arXiv preprint arXiv:1908.08593.
Kovaleva, O., Kulshreshtha, S., Rogers, A., & Rumshisky, A. (2021). BERT Busters: Outlier Dimensions that Disrupt Transformers. arXiv preprint arXiv:2105.06990.
Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). A primer in bertology: What we know about how bert works. Transactions of the Association for Computational Linguistics, 8, 842-866.
Vig, J. (2019). BertViz: A tool for visualizing multihead self-attention in the BERT model. In ICLR Workshop: Debugging Machine Learning Models.