Building Modern Search with Yext: Part 1 - Getting Started
Author: Aaron Pavlick, Developer Evangelist
Products: Answers
Blog Date: January 2022
It's pretty hard to find a website that doesn't have a search bar somewhere. Sometimes it's front and center, and other times it's behind a 🔎 in the upper right hand corner. Either way, you probably use them often when searching the web. But have you ever thought about what goes into building that search experience? I know I didn't until working on a web application at a previous job.
We used an Apache Solr search server indexed with production data so that users could quickly find what they were looking for. The problem was that every time our PM put in a feature request regarding a change to the search experience, the development process looked something like:
- Update the Solr document schema
- Update the ETL that indexed the data
- Refactor the Java-Spring Boot API that we had sitting between Solr and our UI
- Refactor the React-Redux UI to account for changes to the API
I tried to create the most concise list I could for the sake of this guide, but each step could take multiple days depending on a multitude of factors.
I joined Yext as a Developer Evangelist because I wanted to show developers that there's an easier way to build search-based applications. This is the first in a multi-part series around building a modern search-based web application with the Yext Platform utilizing data from IMDB.
Setting up an Account
First, I created an account on Yext Hitchhikers. Hitchhikers is the Yext learning platform where you can learn everything you need to know about our AI search platform. After I've created my Hitchhikers account, I will create a Playground account to begin designing my search engine.
Building a Knowledge Graph
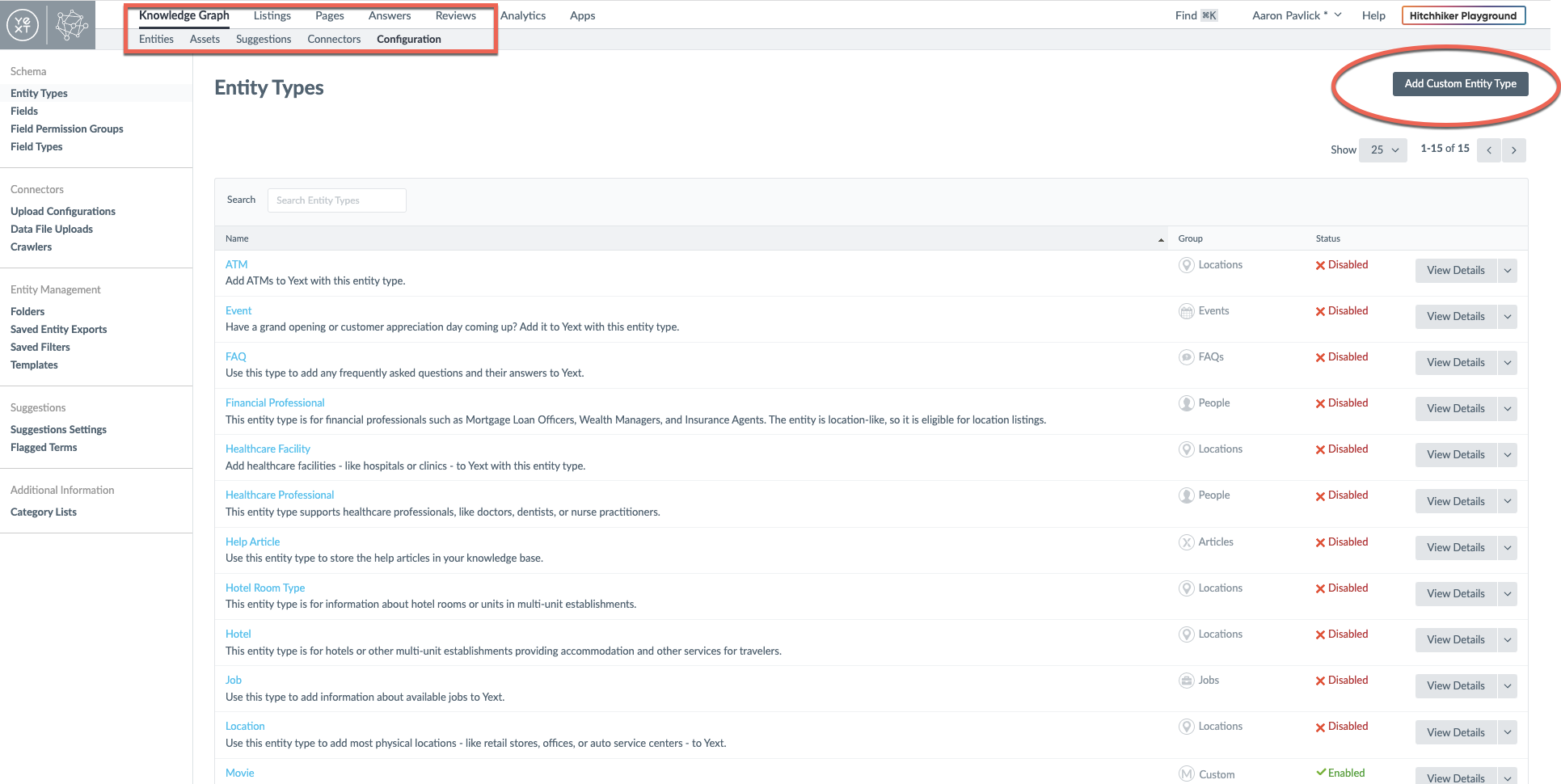
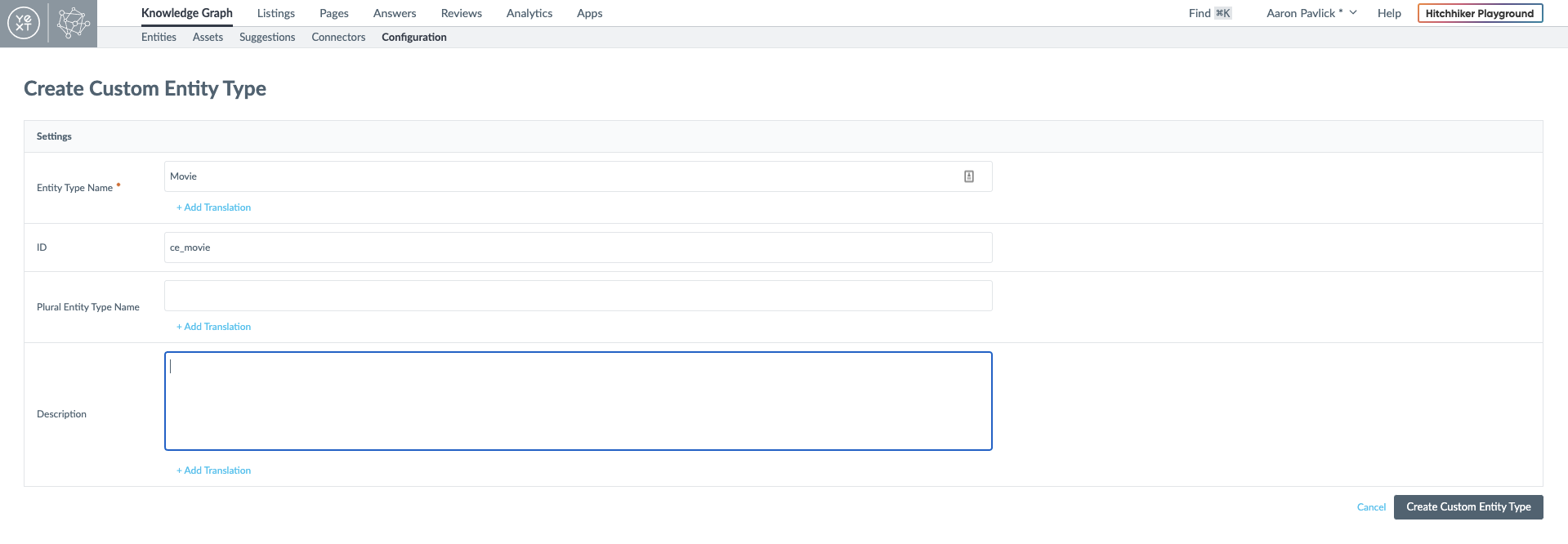
For this example, I'm going to create a search experience based on movie information from IMDB. Yext accounts come with a bunch of pre-defined entity types, but I need to create a custom Movie entity.
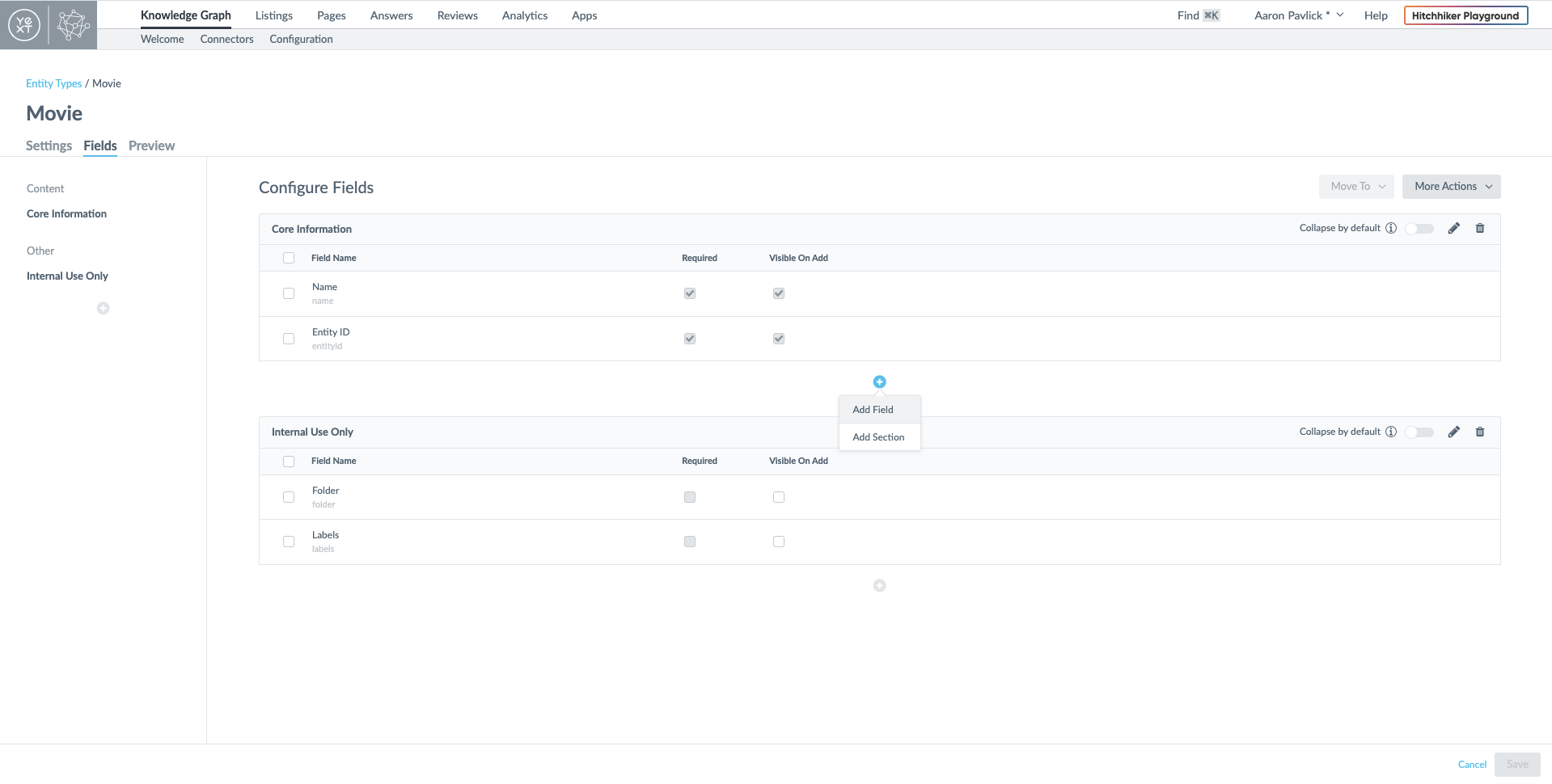
After creating my entity type, I need to add some fields that I will eventually use to search my data and view in my UI. The ID and Name fields are required, but beyond that I could add whatever schema I want to each type. For now, I am also going to add the Custom Fields 'Tagline' and 'Genres'. 'Tagline' is generally a shorter string so I'll set it to the type Single-Line Text. I'm also going to add the built-in 'Description' field.
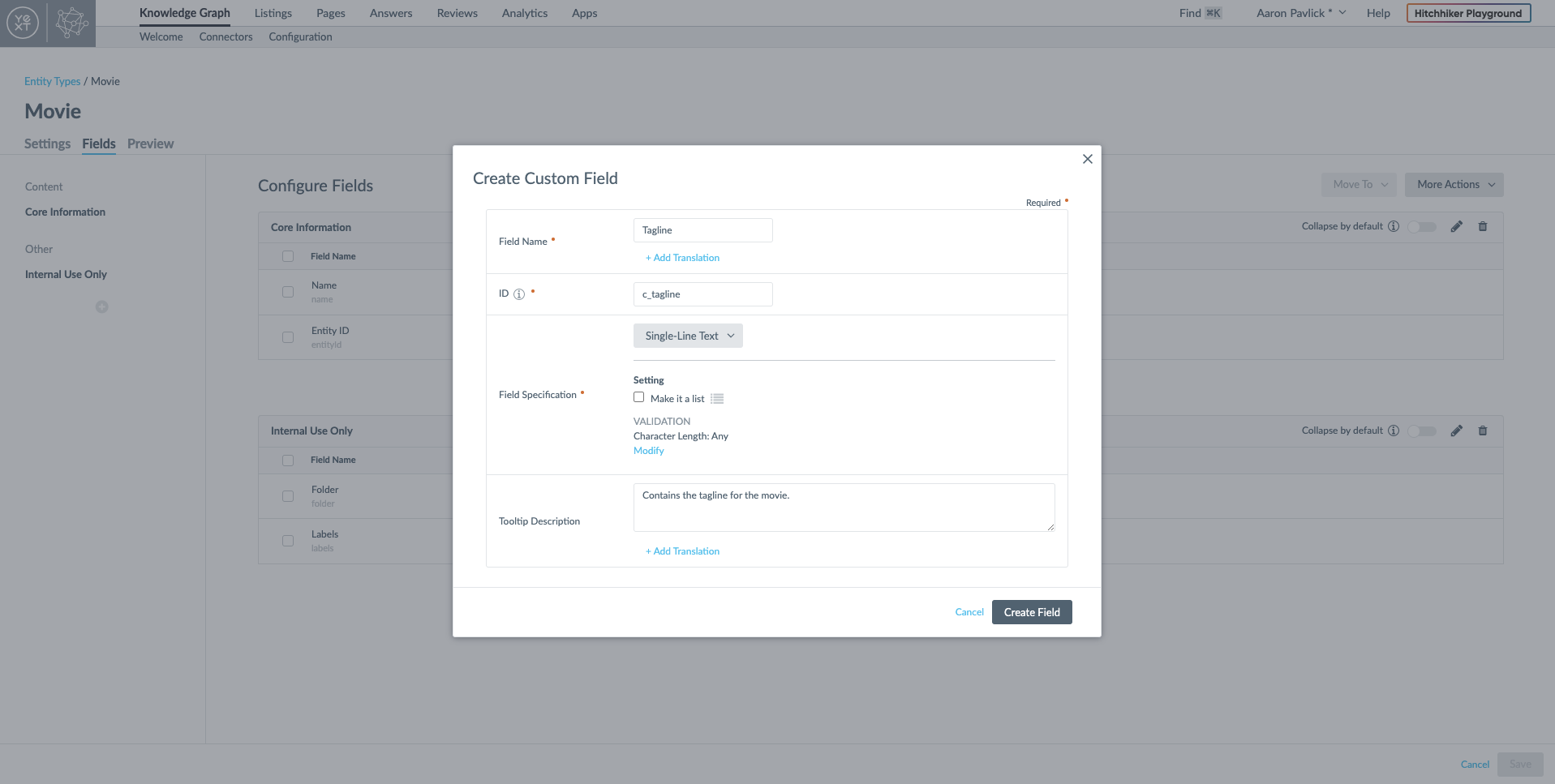
A movie could have multiple genres so I need to make 'Genres' a text list field. I can do this by selecting the Single-Line Text type, but I'll also select "Make it a list" so that it can contain an array of strings.
There's a variety of additional standard field types I could use and I can also create my own custom field types. Now that I've created a my custom entity type configuration, I'll upload 10 entities I have stored in a CSV file.
There are a variety of different ways to add entities to a Knowledge Graph, such as by manually adding individual entities, using one of the pre-built API integrations (Twitter, Shopify, etc.), or building a custom API connector.
Creating an Answers Experience
Having added a few different movies to my Knowledge Graph, I need to create an Answers experience to enable search. An Answers Experience is a search experience powered by Yext Answers. What sets Answers apart from Lucene-based search engines is that it leverages Natural Language Processing (NLP), which uses artificial intelligence to put text or speech into context. I only have a few movies with a few fields in my Knowledge Graph, but that's enough to show off a bit of what Answers can do.
I navigate to the Answers section of my account and click on Create Answers Experience. From here, I name my Answers experience and select the entity I want to search on. I only have Movie entities right now, but I could eventually add new entities like Actors or Directors to expand my search capabilities.
Customizing My Answers Experience
Now that I've created my Answers experience, I need to add a bit of backend configuration. Every search result that is returned by the Answers API is part of a search vertical.
So what is a search vertical? When I go to Google and enter a search query, I am automatically directed to the All results page, but I have the option of selecting from different verticals including Images, Shopping, Maps, Videos, and More.
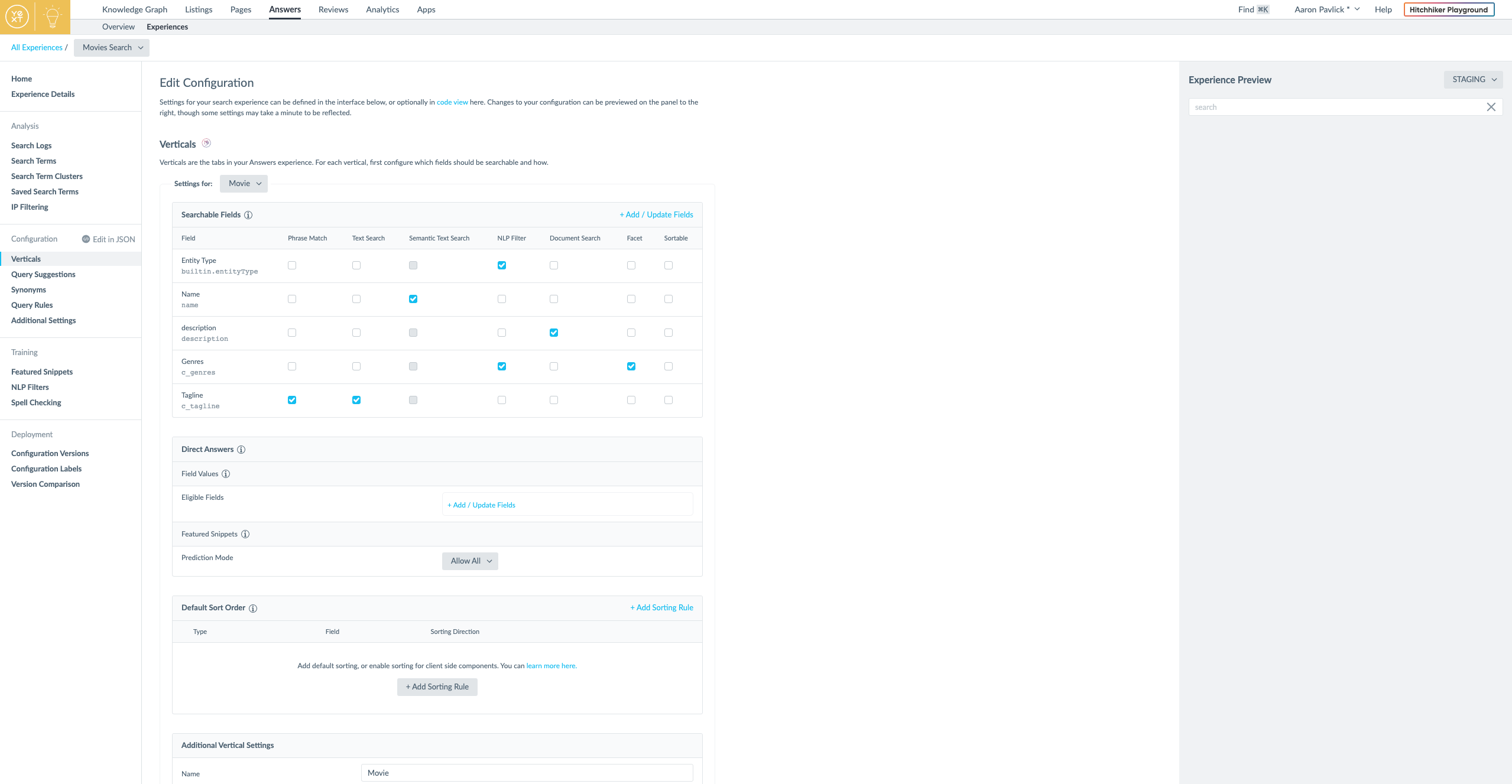
Answers allows me to configure my own verticals that can each have different entities and configurations. I only have movie entities right now, so a movie vertical was created by default. From here, I'll set a few configuration options to get my search working the way that I want.
When I first look at the configuration options for my vertical, see that Entity Type and Name are included as searchable fields by default.
The Entity Type is automatically included as an NLP feature because in the case that a user queries "movies", I want only Movie results to be returned. If I had other entity types in my Knowledge Graph, I would want those entity types to be be filtered out of my search results.
The 'Name' field, on the other hand, should be kept as searchable by 'Semantic Text Search'. Semantic Text Search uses BERT, Google's open-source machine learning framework for NLP, to represent queries as embeddings. Instead of looking for overlapping keywords, Semantic Text Search allows Yext Answers to analyze the meaning behind a query and uses neural networks find the entities that have the most relevant answer. Some notes on the other fields:
- 'Genres' - Since a movie might have 1 or more genres, I have marked it as an NLP filter and facet field. This means that when I search for "action movies", the Answers algorithm will filter out any non-action movies and will return additional facets I could apply after my initial search like "Adventure" or "Comedy."
- 'Tagline' - Movie taglines are usually just short catchphrases associated with a film so phrase match and text search are appropriate.
- 'Description' - I used the built-in 'Description' field for the movie description because it can handle multi-line text containing a few sentences. The Document Search algorithm is applied by default because it knows how to search for relevant text snippets from the description.
I can test my search configuration by either using the Experience Preview within my Yext Account UI or by dropping this cURL command into Postman to see everything that's returned by the Answers API each time a query is made.
Clone and Modify Answers Sample Repo
Now that I have my backend configured the way that I want, I need to start building my search UI. Yext offers a low-code solution for building branded search experiences, but I want more control over the look and feel of my site. I'll use the React starter application that is designed to work with Answers Experiences. First, I'll fork the project into my personal Github. Then, I'll clone it to my machine and rename it.
To display search results from my Answers experience in my web app, I'll first modify answersHeadlessConfig.ts with my API key and experience key. Both can be found by navigating to the Experience Details page within a Yext Account.
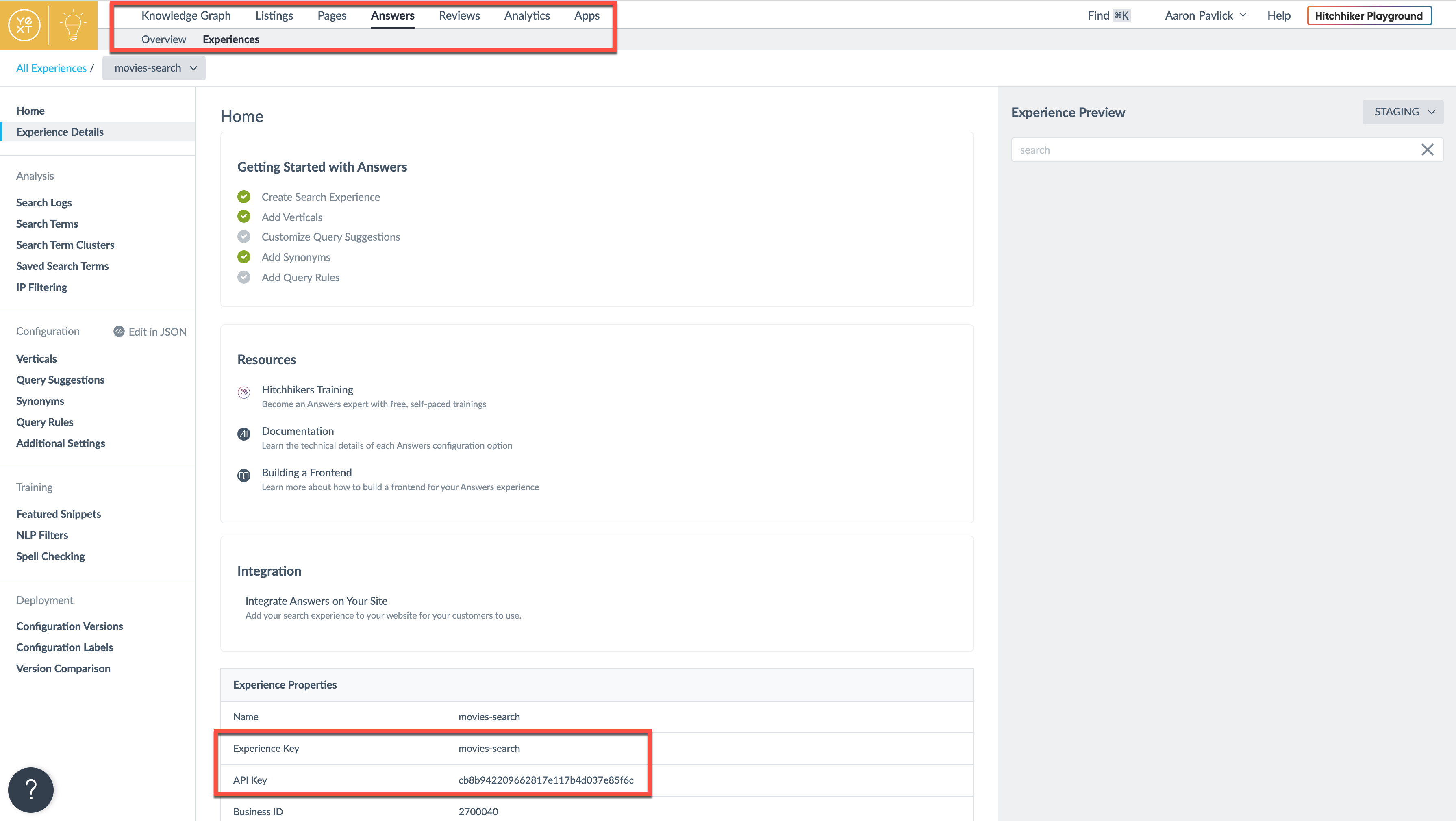
Since I am using a sandbox account, I also need to add the optional endpoints field to my configuration with the sandbox API URLs. Otherwise, the app will use production endpoints by default.
Since I only have one search vertical, I'll remove most of the code in universalResultsConfig.ts and routeConfig.tsx. I can come back to these later once I have to account for new verticals I create later on.
Running npm start in the terminal runs my app locally in the browser. Once the page loads I can try out a few queries. You can checkout the React frontend code for this guide here. In a future post, I'll make stylistic and layout changes to my application.
As you can see in the video above, the 10 movies I added to my Knowledge Graph appear when I load the page. I tried a few different queries to narrow down the results:
- "The Matrix" - This is an exact match of the name of one of the movies in my Knowledge Graph, so it's the only result that's returned.
- "Family Movies" - "Family" matches with one of the genres that "The Iron Giant" and "Toy Story 2" have, and genre is an NLP filter; therefore, they're the only movies that are returned.
- "Tatooine" - This is a string that is contained in the description of "Star Wars: Episode I - The Phantom Menace." I turned on Document Search for the movie description field so the Answers algorithm was able to associate my query with a search result.
Next Steps
Right now, I only have a few search results of one entity type appearing on a plain white screen. In my next post, I'm going to add some more entity types so that I can get some more interesting search results and give my UI a more personal touch. Stay tuned!