The Virtuous Cycle of Machine Learning
Author: Michael Misiewicz, Director, Data Science
Product: Answers
Blog Date: August 2021
Building a great algorithmically-driven product requires a lot of data. You can (and almost certainly must) get some of this data via human labeling, but a great way to really make huge improvements on your algorithms is to get them out in the wild, and measure where they were wrong, so they can be retrained!
The best algorithmic product companies all do this at a large scale:
- Google knows every search engine result page (SERP) served to every user in response to every query, and they know what position link (or widget, or card, or product, or map pin, etc.) is clicked (or not).
- Google also knows every time they show you an ad in Gmail (or around the web, due to their DoubleClick ad network), and whether or not you clicked on it.
- Continuing with Google, reCAPTCHA is another great example. Originally Google used billions of hours of human attention to train their optical character recognition algorithm, and have you noticed how many of the pictures now involve traffic lights and sidewalks?
- Social media companies such as Facebook (both on the big blue app and Instagram) and Twitter can roll out new algorithms for recommending content for your newsfeed, and measure which interactions you have with it.
- Product recommending companies like Amazon and StichFix can deploy new recommeandation models, and measure whether you purchase or return the item.
- Netflix is well known for enormous investments in recommender systems, they can measure clicks and watch time (are you still watching?).
The more you look, the more you see these cycles in many products all around you, especially the ones that seem to have the most magical or impressive algorithmic features. Further, if you look at many of the algorithms underpinning many popular machine learning models, you'll also see this same pattern repeat everywhere. Random forests, gradient boosted trees, neural network optimizers, and reinforcement learning all use this fundamental concept.
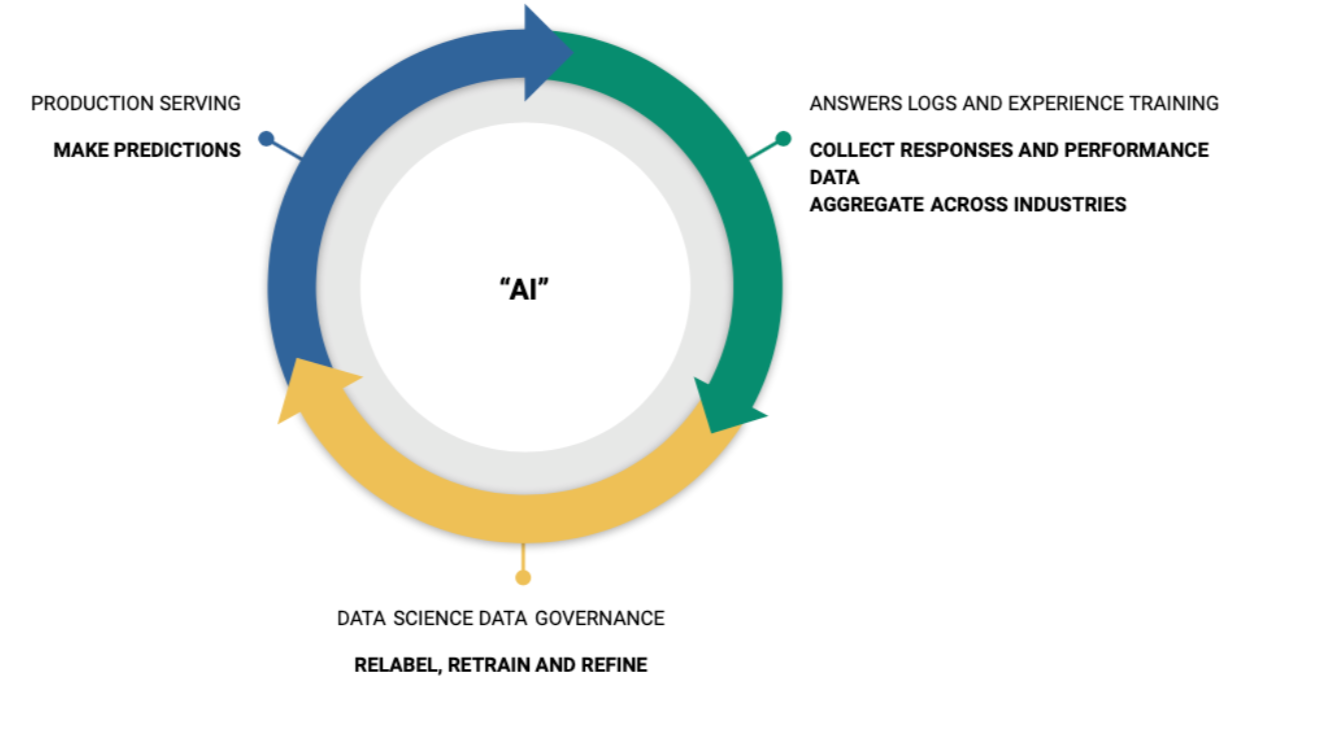
We want to make Yext Answers the best it can be, so how do we go about implementing some of these training loops? Well, for the purposes of fitting a single model to a dataset there are incredibly powerful but also pretty well modularized methods. But how do we do it on a higher level of complexity, that is across a number of systems, functions, features and teams? There's a few objectives we need to optimize.
- Maximize the number of model inferences in production (i.e. serve as many models as possible, on as many searches as possible)
- Maximize the amount of collected feedback and human labeled data (making sure to store everything in a format that allows exploration but also rapid re-training)
- Minimize the time required for data scientists to retrain models and deploy them in production
It's no coincidence that the companies that are most successful in developing algorithmic products also make huge investments in optimizing the 3 points above. If you look at Google's track record of accomplishments (BigTable, Spanner, Borg, Kubernetes, TensorFlow, Tensor Processing Units, etc.), you can see the advanced features which become possible with great infrastructure.
Concretely, what are the data science, engineering, and product teams at Yext doing to speed up the virtuous cycle of machine learning?
- Big investments in warehousing. One of the first and most important systems we built for Answers was a robust and flexible warehouse. We are able to log every request, SERP served, and user interaction event. If any end user clicks a thumbs up or down on a Direct Answer, we log it! This warehouse logs every user interaction with every page, and we use it to fill up labeling assignments for our human data labeling team. Plus, we do it all in a way that is totally anonymous and devoid of any personally identifiable information (PII) or pseudo PII.
- A human data labeling team. Coupled with the user interaction data from the warehouse, we can rapidly find areas we're mispredicting and have our growing team of human data labellers identify and improve residuals.
- Product features to increase the size of our labeled data corpus. This is why we built Experience Training!
- A huge increase in the kind of content that can be served with Yext Answers. This is why we built Document Search. Building the Yext Crawler and Extractors has been essential for growing the corpus of data that can be labeled and used to train new models.
- Big investments in serving infrastructure. We've spent a lot of time making it easier and simpler for data scientists to build and train models in the critical path of Yext Answers, and this has included a lot of research into specific hardware accelerators and configurations to make everything function within appropriate latency and quality thresholds. As of this writing, we have 37 models that serve in the critical path. That is up from two in June of 2020. Further, back in June of 2020 it took us about a month to deploy a new model, but now we retrain nightly.
- Internationalization. We're expanding our labeling team to include more language expertise! Expanding languages supported is a great way to increase the number of inferences in production.
Thanks to this continued investment, I am confident that Yext Answers will continue to expand and improve. We're doing large amounts of R&D work to improve quality, from making it easier to add content to the Knowledge Graph, understand query intent better, and improve and expand direct answers.