Deep Dive into the Yext Crawler
Author: Kevin Liu, Software Engineer
Product: Crawler
Blog Date: December 2021
Yext's Crawler is a web crawler that enables scraping the unstructured web at scale. Together with Connectors, which convert the scraped data into structured entities, the Crawler enables brands to quickly load their data into Yext's Knowledge Graph. This minimizes the manual work needed and expedites the setup required to use various other products such as Listings, Pages, and Answers.
By running the Crawler against their own web pages and then using Connectors, brands can load their entities into Yext and sync their data to Yext's Knowledge Network automatically. For example, administrators can use the Crawler to scrape a Frequently Asked Questions page on their website and power their site search with Answers, thus utilizing the capabilities of AI search over an outdated keyword search.
Before we dive into the specifics, here's a quick rundown of the terminology we use when talking about Crawlers. A single brand (aka the user) can have multiple Crawlers, and each Crawler can have multiple execution requests where each request represents a particular run of the Crawler. Each execution request consists of multiple tasks, where each task represents a single page crawled.
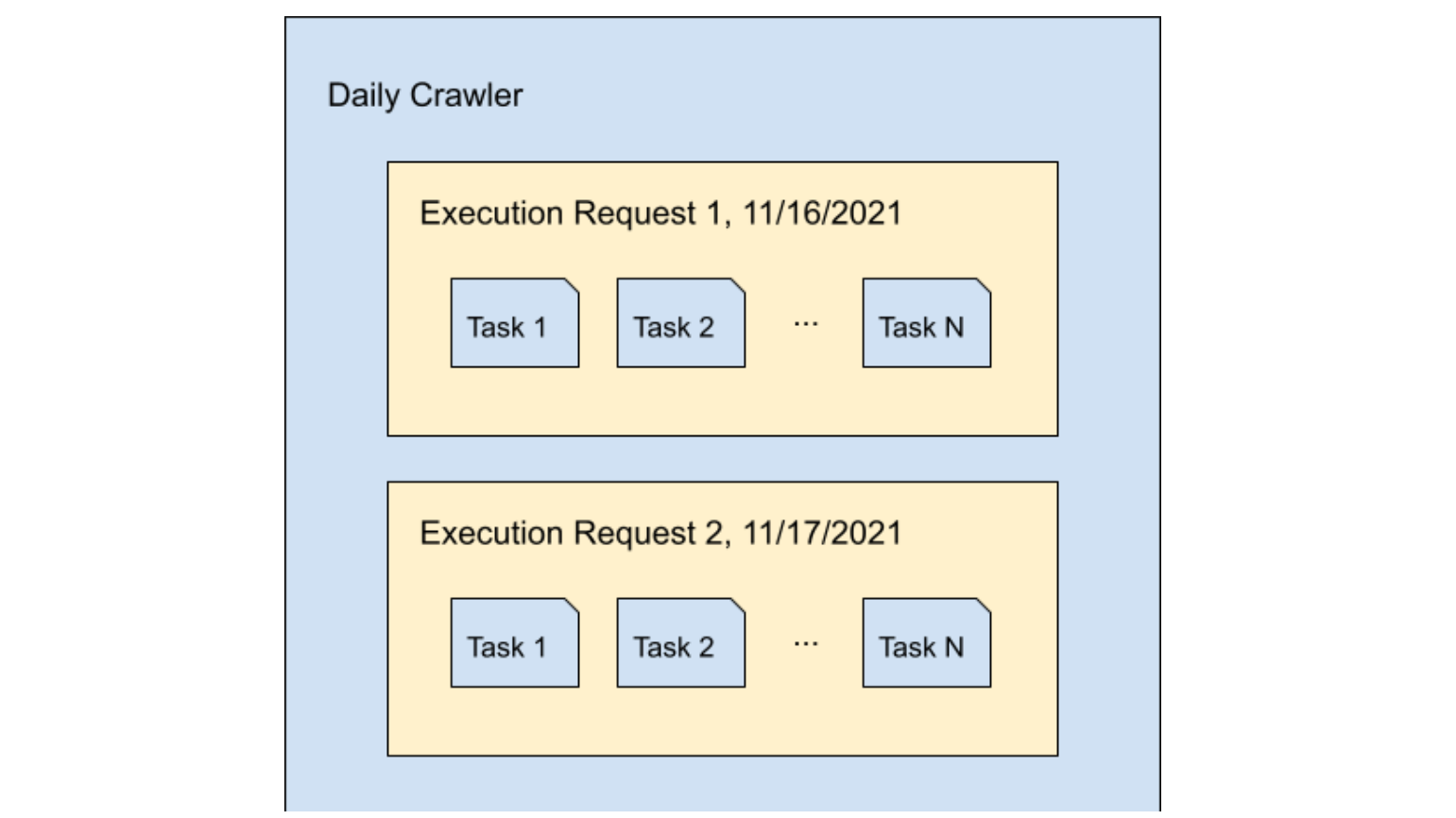
Consider a business with a Crawler configured to crawl all pages found on its domain — www.examplebusiness.com — at a daily cadence. That Crawler will create an execution request every single day to crawl all pages on www.examplebusiness.com. Tasks will then be created for each link it visits within this domain, such as www.examplebusiness.com/product1 and www.examplebusiness.com/locations.
High-level Architecture
When a Crawler is run, an execution request is created to track the state of the crawl as a whole. From this request, an initial set of tasks is generated and stored in the database. Stored tasks are regularly fetched from the database and fairly scheduled (see the Fair Scheduling section) for scraping by scrapers hosted on EC2 instances in AWS.
Crawl execution requests for Crawlers are broken down into tasks by servers in Yext's data center before they are forwarded to our AWS-hosted scraper pool for execution. After a scrape task is completed, the scraped content is sent back to Yext servers for processing. Processing the results involves extracting some basic metadata and storing that alongside the scraped content.
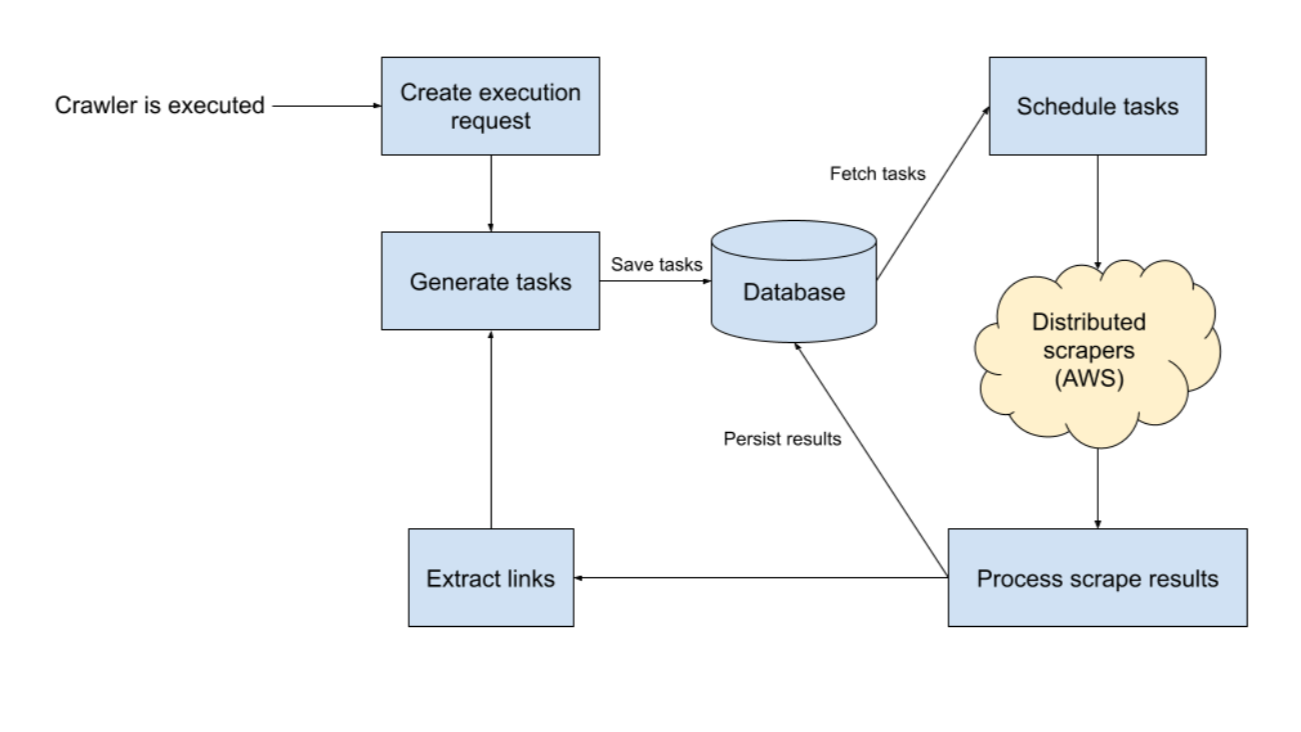
To prevent storing duplicates of the scraped content, we store a hash of the content to detect whether or not a page has changed since the last scrape. If a page hasn't changed, then the scraped content doesn't need to be saved again. In addition to storing basic metadata and content, any URLs that are present in the content are also extracted. The Crawler supports three different strategies for handling URLs: Specific Pages, Sub Pages, and All Pages. Each strategy specifies the relevancy of extracted URLs — Specific Pages matches specific URLs, Sub Pages matches all pages under a URL prefix, and All Pages matches all URLs.
After extracting all URLs from the content, the URLs are further filtered down to those that are unvisited and relevant, and the filtered URLs are then used to generate new tasks for scraping.
This cycle of scraping and processing, more commonly referred to as spidering, continues until there are no more URLs for the Crawler to visit.
Scalability
The Crawler is capable of scraping over a million pages per day. The distributed scrapers themselves are configured to automatically scale out as crawl requests grow by leveraging Amazon EC2 Auto Scaling. As requests grow, more EC2 instances will be spun up for more scraping throughput; when the requests die down, the excess EC2 instances will be killed to remove idle scrapers.
All other steps of the crawl process, which are hosted within Yext's data centers, can easily scale horizontally with the addition of servers as needed.
Error Handling
With the variability of websites that the Crawler is tasked with handling, a variety of errors will inevitably emerge. These errors fall into two categories: permanent and transient errors.
Permanent errors are, as the name suggests, errors that will persist despite any number of retries. For example, despite a successful scrape, a page may return no content at all. In cases like these, the error is simply propagated and reported back to the user.
The other class of errors, transient errors, are temporary and can often be remedied by retrying the scrape. For example, the Crawler may encounter a website that is temporarily down as a result of external factors, such as a cloud provider outage. The Crawler utilizes exponential backoff to retry such tasks in the hopes that, given enough time, the task will eventually succeed. Exponential backoff increases the time between retries at an exponential rate, as stretching out retries over a longer period of time allows the task a greater chance to recover and succeed.
Fair Scheduling
With limited resources, the simplest approach to scheduling scraper work is to insert all the tasks into a first in, first out (FIFO) queue. Each customer can have multiple Crawlers, and at peak usage there could be multiple ongoing crawls per customer. Each ongoing crawl will be executing a particular request, which itself can have up to 100,000 tasks. The FIFO queue works well when the number of tasks per execution request is small relative to the number of scrapers available, but this approach quickly runs into issues as this ratio grows.
If one customer has an enormous number of tasks for a single crawl, those tasks can quickly end up consuming all of our scraping resources. The consequence is that crawls from other customers will be blocked as they wait for scrapers to become free. This leads to poor user experience, as the end user could end up waiting hours for their crawl to start, even if their execution request has a small number of tasks.
In order to schedule tasks more fairly, we allocate three quotas according to these measures of priority: the age of a request (oldest first), whether this is a Crawler's first request, and at least two tasks from each execution request. There can be some overlap between each quota – the tasks from the oldest request can overlap with the two-task minimum from each request, for example – and this is taken into account when determining the exact sizes of each quota.
First, allocating quota to the oldest tasks ensures that we can set a reasonable upper bound on how long a user will have to wait for a task to be processed. Second, allocating quota to the tasks belonging to a Crawler's first execution request ensures that a new Crawler will have results as soon as possible. Lastly, at least two tasks are scheduled from each execution request at a time, guaranteeing that we are pulling in tasks from all execution requests. This prevents a single large execution request from hogging all of our scraping resources.
Conclusion
Through a combination of scalable architecture, exponential error handling, and fair scheduling we've developed a Crawler that can support high usage loads while simultaneously maintaining the same Crawler experience across all customer accounts regardless of size. By making the Crawler easy and accessible to use, it drastically cuts down on the time needed to load entities into the Yext Knowledge Graph and start using Yext's other products.
While the Crawler's main architecture has already been well-defined, we are constantly adding new features to it. In the future, we plan on adding support for crawling authenticated sites (where a user must login to view the content) and crawling various file types such as PDFs and images.