

Step 3: Domains Source Type Settings
If you’ve chosen Domains as your source type, choose your crawl strategy and specify the pages to include in your crawl. Then, choose how you want to handle query parameters on any crawled URLs.
If you’re using the Sitemap source type, continue to the next step of this guide.
Crawl Strategy
The crawl strategy determines which pages should be crawled to from your specified web domain.
A crawler can crawl all pages on the domain, sub-pages (e.g., if the specified domain is www.galaxygrill.com, then www.galaxygrill.com/locations would be a sub-page), or only specific URLs.
From the Crawl Strategy dropdown, choose from the following options:
- All Pages
- Sub Pages
- Specific URLs
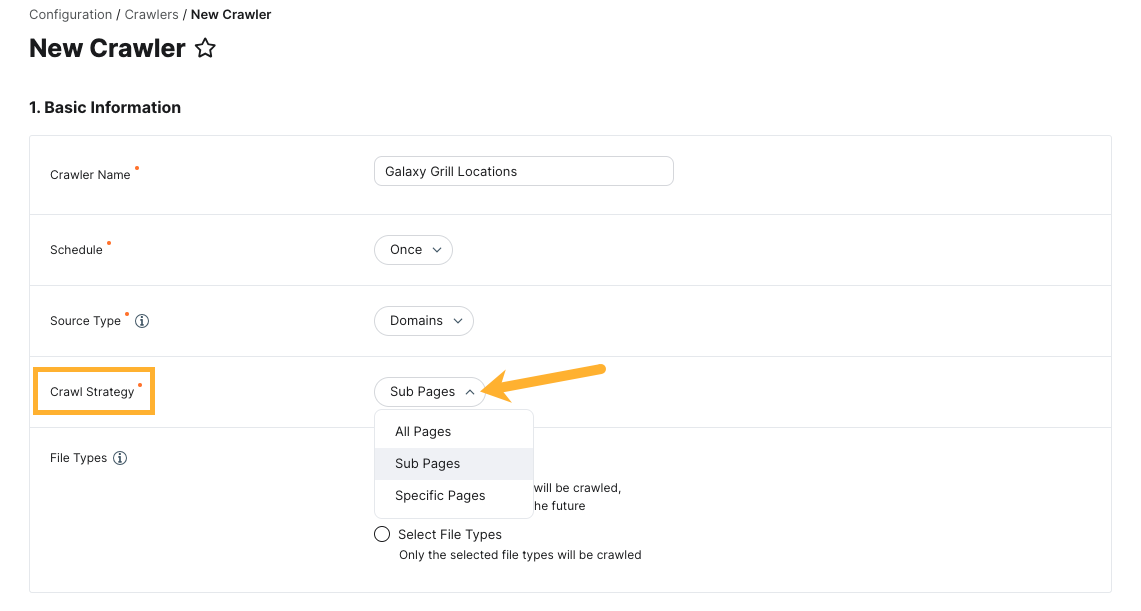
Which Pages or Domains Would You Like to Crawl?
Under the Pages or domains to crawl option, specify the URL(s) where you want the crawler to begin crawling (and finding other pages to crawl to). These URLs are also referred to as start domains or start URLs.
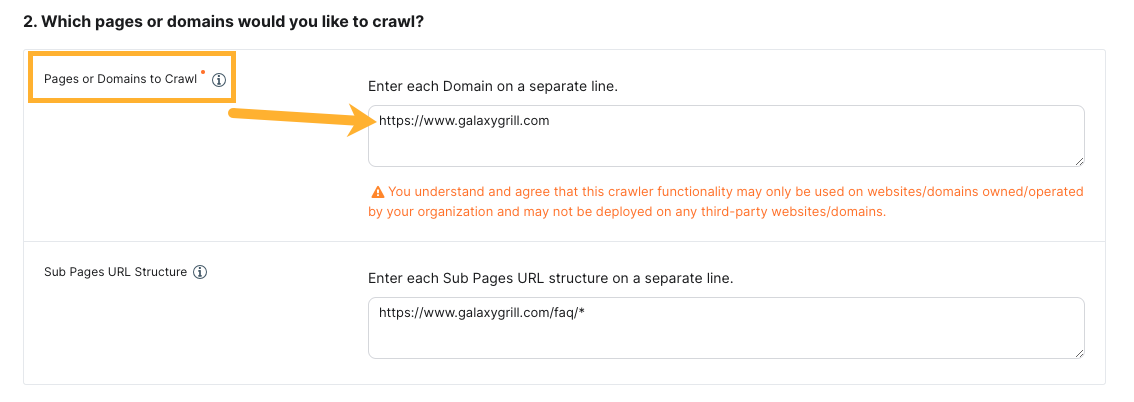
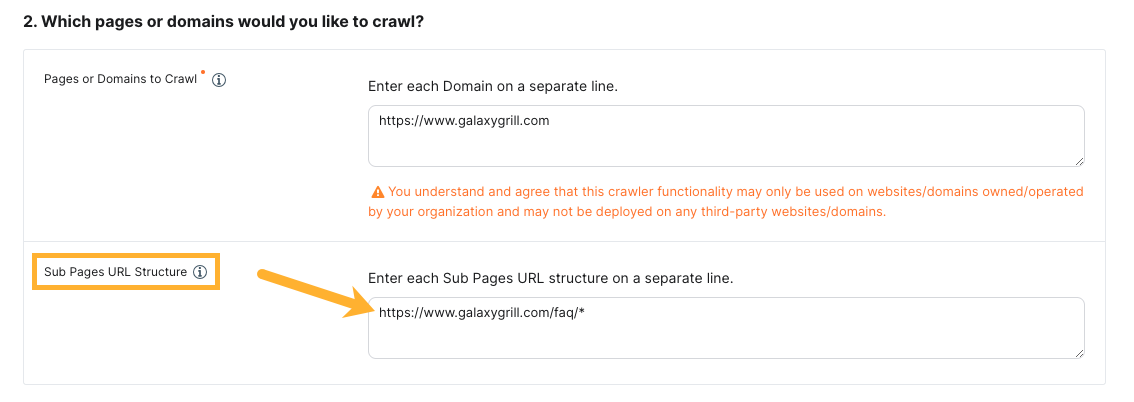
Sub-Pages URL Structure
You can use the Sub-pages URL structure setting if you want to crawl pages on certain sub-directories of a web domain while excluding others. This setting is optional and works with all crawl strategies.
Specify your sub-page URL structure with
wildcard notation
(e.g., www.galaxygrill.com/faq/*)
For example, if your start URL is www.galaxygrill.com, and you want to crawl pages under www.galaxygrill.com/faq, but not www.galaxygrill.com/locations, you could set up your sub-pages URL structure as shown below:
Which URLs Should Be Omitted from the Crawl?
In this section, specify any URLs you want to blacklist and set your query parameter specifications. These are both optional.
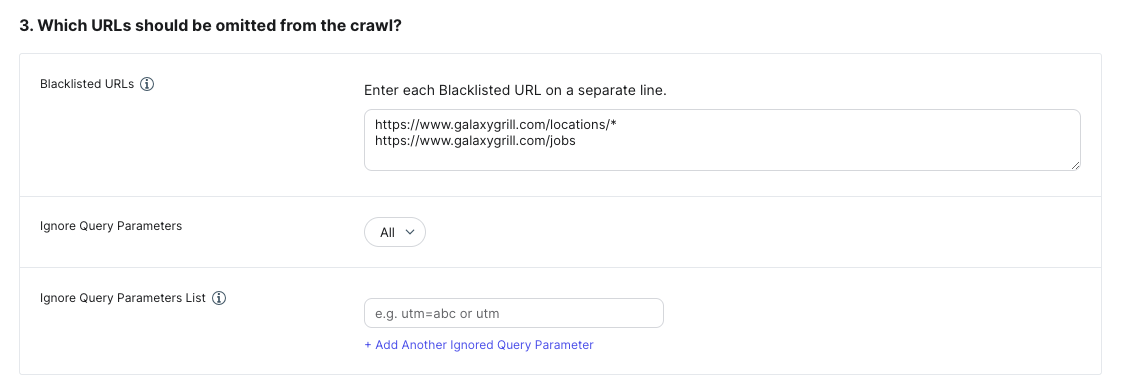
Blacklisted URLs
Exclude specific URLs from a crawl, even if they match your chosen crawl strategy and other settings. Enter each URL to blacklist on a separate line. You can also use wildcard notation here.
Query Parameter Settings
Choose how query parameters should be handled on any crawled URLs.
For example, if query parameters are ignored, the crawler would see www.yext.com/blog and www.yext.com/blog?utm_source=google as the same URL. In this case, ignoring the query parameters would prevent the crawler from crawling that page more than once.
Choose from the following settings:
- All: All query parameters are ignored
- None: No query parameters are ignored
- Specific Parameters: The parameters specified in this setting will be ignored.
Advanced Crawler Settings
Set the rate limit and maximum depth of pages to be crawled from the start URL.

The rate limit determines how many tasks the crawler can execute on a site at one time, without impacting site performance.
By default, this is set to 100. You may need to consult your web team in order to determine an ideal rate limit for your site.
The max depth is the number of levels past the start URL that the crawler will spider to. For example, if your start URL is www.galaxygrill.com and this page links to www.galaxygrill.com/faq, the faq page would be one level beyond the start URL.
By default, the max depth is set to 10.
Save Crawler
Once you’ve configured your crawler settings, click Save Crawler at the bottom of the screen. Then, continue to the Create Connector step of this guide.