
Overview of Algorithm and Indexing | Yext Hitchhikers Platform
What You’ll Learn
By the end of this unit, you will be able to:
- Define tokens and explain how they impact ranking logic
- Explain how the multi-algorithm approach works
- State how the Search algorithm ranks verticals
Overview
An algorithm is simply something that takes a series of inputs, conducts a sequence of actions, and then returns outputs. As a reminder from the The Search Query Journey unit, the algorithm evaluates the results for each vertical separately, and then ranks verticals against each other to combine the results.
Let’s break this down further. The Search algorithms takes a series of inputs, such as:
- The user inputted query
- The user location
- The Search configuration to know how to treat each of those intents and any business logic
- The Knowledge Graph to map those intents to specific entities in the Yext platform
With these inputs, the algorithm will first break down the query into tokens to determine what exactly to search for. Then it’ll use a multi-algorithm approach based on the type of content you’re searching on to determine the best results for each vertical. This includes the list of entities, any direct answers, and any detected filters. Finally the algorithm ranks verticals against each other.
This unit covers levers that affect the search algorithm that you can configure. For a more in-depth look at how the Search algorithms work, check out the Search Algorithms reference docs.
Tokens
Tokenization is breaking down a query into discrete units - aka, words! Tokens are used to determine the candidates for matching to searchable fields. To derive tokens, we’ll split out individual words based on white space, strip out casing and punctuation, and ignore common words (called ‘stop’ words) that do not add meaning to the query.
For a query like “What are your products?” the token derived here would be ‘products’. A candidate for token matches might be an entity type of ‘Product’.
How Synonyms Impact Tokens
Synonyms allow us to translate the tokens to different variations that mean the same thing. For example, although we might have ‘jobs’ as an entity type in the platform, we might want the same results to show for ‘careers’, ‘positions’, or ‘vacancies’. You’ll learn more in the Synonyms unit.
How Stop Words Impact Tokens
As noted above, to derive tokens, our algorithm will treat “stop words” differently. The Search algorithm has a built-in list of stop words, such as of, the, and in. These words can distract from the important tokens of a query (e.g. “the best bankers in the tri-state area” becomes “best bankers tri-state area” focusing on the entity, the rating, and the location).
Stop words are treated differently depending on which algorithm is used:
- Keyword Search - stop words are given a much smaller weight than other words in a query when matching on keyword search fields. This means that while they’re not completely ignored, stop words have a smaller and smaller effect as query length increases. Additionally, since keyword search is entirely based on token matches, stop words are used for token matching (and thus may return results) when no non-stop words are present.
- Inferred Filter - stop words can still be matched in filters, but the Search algorithm will not match an inferred filter that only matches stop words. For example, if you have an inferred filter for “Cancer Care” and a stop word for “care”, the query “Cancer Care” will pull this filter. However, if you search for “Urgent Care”, it will not match on this filter.
- Semantic Search - stop words can still be matched on fields with semantic search since this algorithm uses a combination of token matching and semantic similarity scoring. In other words, results with stop words may return if they are semantically similar enough to the search query.
Set additional stop words with the additionalStopWords property. Learn more in the
Search Config Properties - Top Level
reference doc.
How Custom Phrases Impact Tokens
Custom Phrases are multi-word phrases that the algorithm will treat as a single unit when matching results in Search. This can be useful for listing brand-specific phrases that you do not want partially matching with results.
Custom phrases only affect how fields using keyword search, phrase match, or inferred filter are searched because these three algorithms rely on matching keywords between the query and field values. However, if a field is searched using semantic search, the semantic similarity between the query and the field value may return a result that only partially matches with a custom phrase.
For example, a taco shop might add a custom phrase “corn tortilla” to prevent a query for “corn tortilla taco” from returning results like “corn on the cob”, “ tortilla soup”, or “corn salsa”. If this field is searched with semantic search, a query for “corn tortilla” could still return “flour tortilla” – even if “corn tortilla” is added as a custom phrase – because they are semantically similar.
Search Operators
Search operators allow users to control the logic for how tokens are combined when performing keyword search. Operators are case sensitive and typo-intolerant. The four operators available are:
- AND between two tokens requires both tokens appear in a searchable field (e.g. “red AND dog”)
- OR between two tokens requires either of the tokens appear in a searchable field (e.g. “blue OR cat”)
- NOT before a token requires the token does not appear in any searchable field (e.g. “NOT yellow”)
- Double quotes around a phrase requires the entire phrase to appear in a searchable field
These operators can be used individually or combined to apply more complex logic to the tokens included in a keyword search. Check out the Search Operators reference doc for more info.
Multi-Algorithm Approach
Within each vertical, we take a multi-algorithm approach with Search depending on the type of content we’re searching through. Different types of content need to be searched differently. We have algorithms for three different types of content: structured data, semi-structured data, and unstructured data. You choose how you want each type of content to be searched on by setting searchable fields in the configuration (you’ll learn more about this in the Searchable and Display Fields unit).
For the full details on each algorithm, check out the Search Algorithms reference doc.
Structured Data: Phrase-Based Searching
For structured data with inferred filtering configured, the algorithm will look for a field value’s tokens in the query (i.e. ‘blue hat’ or ‘doctors who accept blue cross blue shield’) and apply those tokens as a strict filter. This works great for structured entities like products, events, and jobs.
The algorithm uses Named Entity Recognition (NER) for location search based on the user’s proximity bias and the prominence of the place.

Semi-Structured Data: Semantic Search
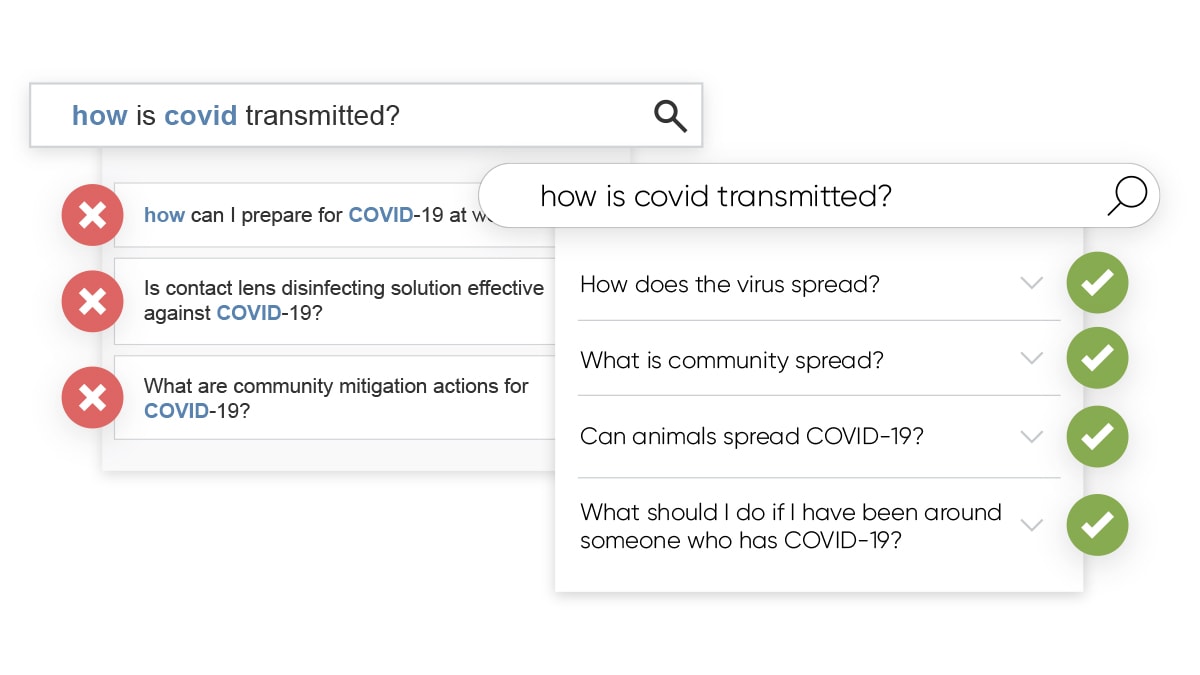
Yext Search uses semantic search for FAQs and Help Article names. This content is more loosely structured than entities like products, events, or jobs. Instead of relying on keywords, we embed the search query and FAQ or Help Article names in vector space and use an algorithm to determine the most relevant FAQ or Help Article. Our semantic search algorithm is able to identify FAQs and Help Articles that are similar in meaning to the user’s question. For example, we’ll identify that a query of “how is covid transmitted?” is semantically similar to “how does the virus spread?”. No synonyms required!
Unstructured Data: Keyword Search and Document Search
The most basic algorithm offered today is keyword search, which relies on keyword matches between the query and the result. When you enable keyword search on a field, Search will return results whenever there is a match between a query and field token, unless they are stop words. When ranking results, Search considers the relative importance of the token with respect to all of the Knowledge Graph.
Document Search uses the keyword search algorithm to search on long-form documents. You can crawl, index, and search through blog posts, help articles, and product manuals. It then uses extractive QA to pull out relevant snippets that answer the query posed.

Entity Ranking Logic
Once the algorithm has found the most relevant results for the user’s search term, it must then decide how to rank those entities within the vertical. Ranking logic will be overridden by any custom sorting configured (check out the Sorting (Backend) unit). To do so, it considers the following elements:
- Location radius with location intent: If location intent is present in a query, we want to filter down the results to entities within an appropriate radius of that location.
- Relevance: Sort based on relevance to the query
- Number of matched tokens
- Number of non-matched tokens: For entities with the same number of matched tokens, one with more non-matched tokens would rank lower
- Location distance: Sort based on proximity to the user’s location or the specified location
Vertical Ranking Logic
Vertical ranking is all about how we show different categories (or “verticals”) of content - e.g., FAQs, Locations, Help Articles, etc. - in the most helpful order to address the user’s search query. Getting vertical ranking right is hugely important to ensure users see the most relevant answers to their questions, and to achieve the highest levels of user engagement and ultimately, satisfaction.
So how does vertical ranking work in Yext Search today? It works in a series of three (3) steps, which are performed in the few seconds between a search being placed, and the results being shown.

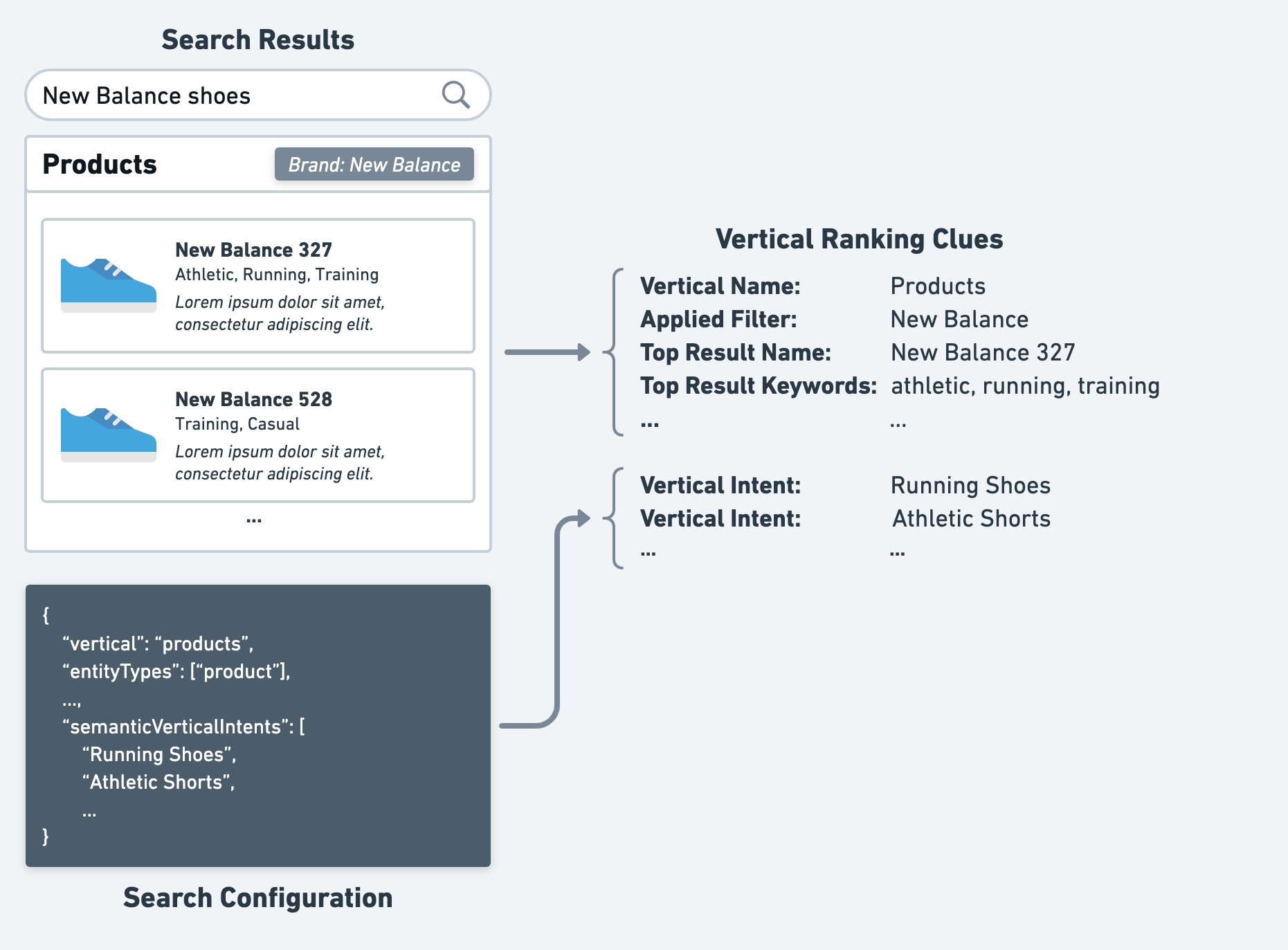
Step #1: Gather Clues
First, for each vertical returned in a search, the Search algorithm gathers clues that can be used to gauge how relevant that vertical is to the user’s search. For example, this might include things like:
- The name of the vertical
- Any filters applied on the vertical
- Fields from the top result of each vertical
- Any vertical intents provided in the configuration for that vertical
Step #2: Generate Vertical Scores
Second, with all of these clues gathered for each vertical, Yext Search will then compare each clue semantically to the user’s query, meaning it will evaluate how “close” they are in meaning. This works very similarly to how semantic search works (in fact, they use the same machine learning model).
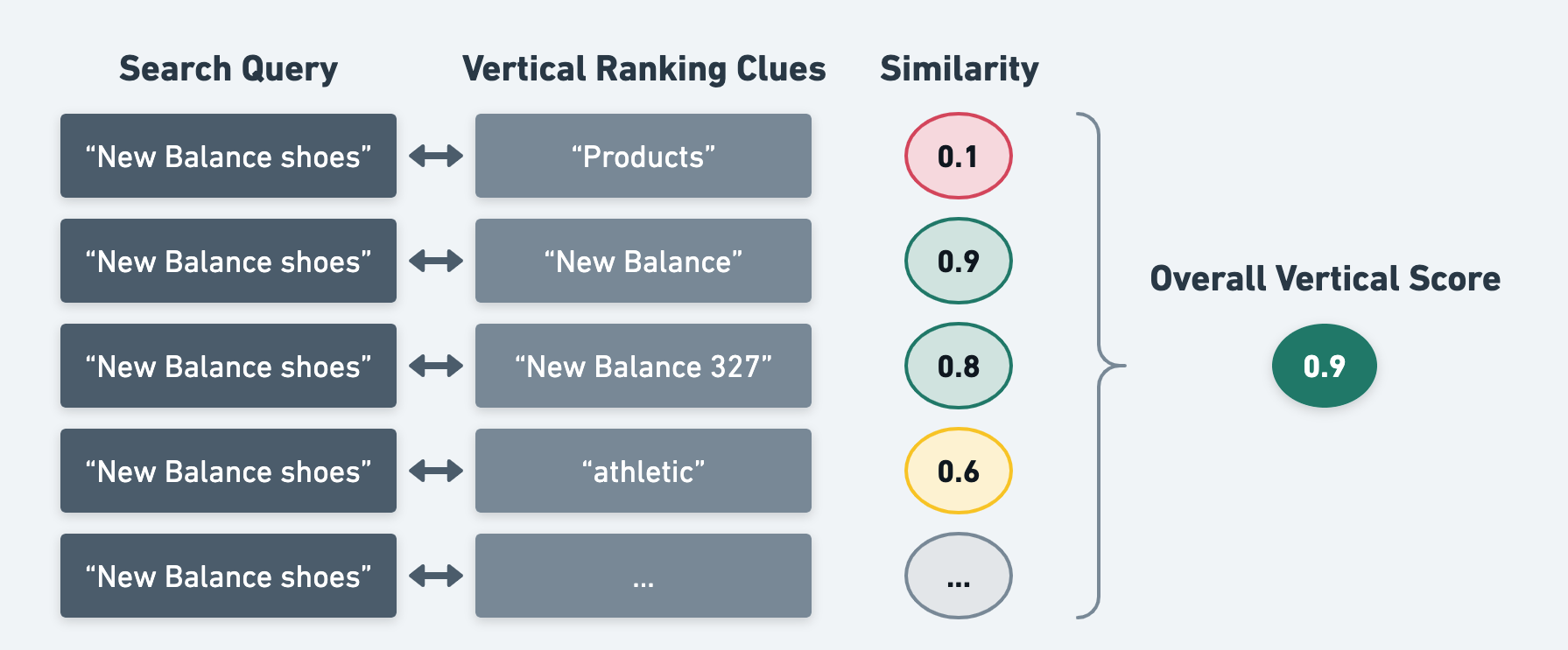
After Yext Search has evaluated all of the clues for each vertical, each vertical will receive a score between 0 and 1, which indicates how relevant Yext Search thinks that vertical is to the user’s query.
Step #3: Rank!
Finally, with a score assigned to each vertical, Yext Search will simply rank each vertical based on that score.
![]()
This is also where two additional properties - Thresholds and Biases - come into play.
- Thresholds are minimum score requirements that a vertical must meet in order to be returned at all in the search results.
- Biases are adjustments you can make to the final score of each vertical, which determine the rank in which they appear. A positive bias will be added to the vertical score, and a negative bias will be subtracted.
There’s one caveat to vertical ranking - the vertical that produces a displayed featured snippet will be ranked first, overriding any other vertical ranking logic. This is because the featured snippet directly answers the user’s query, so it is the most relevant.
You can set intents, thresholds, and biases in the Search configuration for each vertical, which allow you to influence the final ranking of verticals. We will discuss these properties and how to best use them in the Vertical Ranking unit.
Other Components Controlled By the Algorithm
The algorithm impacts more than the results that are returned after a user submits a query, including:
Query Suggestions: Every time you interact with a search bar, a request is sent to the Search API. When you first click into a search bar, an empty request is sent, and the API returns hardcoded prompts. As a user starts typing, we will see queries that begin with the search term entered, known as our popular queries. Learn more in the Query Suggestions unit.
Spell Check: For a given query, the Search API is able to return spellcheck corrections to your query. Clicking on the suggestion re-runs the search with that spelling. Each client has a separate spellchecking dictionary made up of a generic dictionary for the supported language, historical search queries, and your Knowledge Graph. Learn how to train spell checking in the Experience Training unit.
What best describes a token in the context of search?
How should we think about how to break up the categories in the multi-algorithm approach?
Which algorithm does Yext Search use to rank verticals?
A Hitchhiker in the making! 🔥
