

AI Data Cleaning Transform (Preview Feature) | Yext Hitchhikers Platform
Overview
Using the AI Data Cleaning transform, you can now harness the power of Yext’s advanced machine learning capabilities within the Connectors framework to quickly and easily transform your input data into a desired output state. This new Transform takes in a task description and 3 examples of input/output data , extrapolates the desired output state, then intakes an entire column of ingested data and auto-magically generates cleaned outputs.
Prerequisites
- Under your Account Settings, enable Fall ‘22 Release: AI Data Cleaning Transform (Preview) in your account
- You’ll need to be logged in as a user with permission to manage Connectors. To use the transform in a Connector, you can choose to use any Source. Follow the Data Connector Module to get started.
Limitations & Recommendations
- This transform can ONLY be USED for data sets UNDER 50 ROWS
- This is temporary – check back in the coming weeks for improved support!
- We do NOT recommend using this in any production environment. The accuracy of the transform is not 100%. The connector framework works by applying the transform at scale during a run, at which point the data will directly sync as entities to Yext Content. Data using this transform may not product 100% accurate outputs, so you should avoid syncing data with the transform to be used directly in production.
- NOTE: We plan to add support to ensure humans can review outputs sufficiently in order to ensure this transform is usable in production in the future.
- NOTE: We plan to add support to ensure humans can review outputs sufficiently in order to ensure this transform is usable in production in the future.
- English is the only language we support at this time – make sure that your ingested data is in English.
- Processing times can be lengthy. This means that the preview table can take longer than usual to load, and the actual run time of the connector may be significantly longer when using the transform.
Steps
To understand how to successfully implement this transform, we’ll walk through the setup using the following example:
Given a string of variable text (like promotional messages), you want to extract the price value so that it can be mapped to a field in Yext Content.
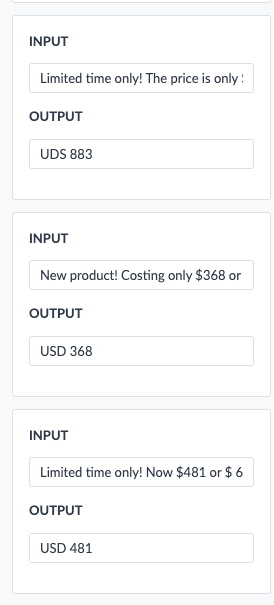
| Ex. | Input (Text) | Output (Price) |
|---|---|---|
| 1 | Limited time only! The price is only $883 or $ 41.91/mo. for 6 mo. | USD 883 |
| 2 | New product! Costing only $368 or $ 43.52 / mo. for 24 mo. | USD 368 |
| 3 | Limited time only! Now $481 or $ 68.38 / mo for 24 mo. | USD 481 |
![]()
Once you select the AI Data Cleaning transform, you’ll first need to specify the column of data to be transformed.
Once that Column is chosen, you have the option to either:
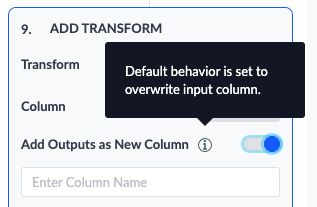
- Overwrite the input column values with the returned output values → this is the default behavior of the transform
- Add Outputs as New Column → if toggled to true, then the input column will remain unchanged and all output values will populate a new column of data. In this case, you will also be required to provide a name for the new column.
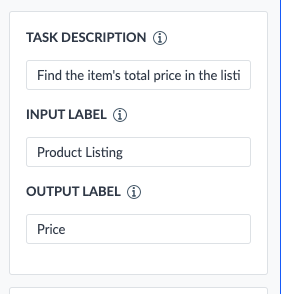
Next, you’ll need to provide a Task Description, Input Label, and Output Label, which can help improve the accuracy of the results.
The Task Description should be a specific sentence that describes what you want the transform to accomplish. The key is to be as specific as possible. For the example above, a good task description might be:
- “Find the item’s total price in each product listing.”
The input label should be a word or phrase that describes the input data. For the example above, a good input label would be “product listing”, which is descriptive and directly referenced in the task description.
Similarly, the output label should be a word or phrase that describes the desired output data. For this example, “price” would be a good choice.
Finally, you’ll need to specify 3 input and output examples. The input examples should be reflective of the entire dataset you plan to transform, and the outputs should be what you would like the model to generate.
As shown in the table, those input and output values can then be provided as part of the transform configuration.
By default, upon initial configuration, the input values will be pre-populated with the first 3 distinct, non-null values of your specified input column. However, you can choose to overwrite these values with any input examples you like. You’ll then just need to fill in each output textbox with the output data that each specified input should produce.
NOTE: Blank values are not valid inputs or outputs. While this may change in the future, the current model will only transform non-null values, and all output examples must have a non-null value.
When the transform is applied to the entire data set, all blank rows will remain blank after the transform is applied.
As a final step, you can optionally choose to validate your output data against a Yext field type. For example, if your output data is a date extracted from a string of text, you may want to make sure that the output data format you’ve specified matches that of a Yext date field format.
When toggling “Validate Outputs” to true, you’ll see a dropdown select of field types. When you select a field type, you can see if your output data would be valid. So for example, if you choose to validate your outputs against the date field type, an output of 7/22/2022 would show that it is valid, but an output of 07-22-22 would be invalid. This feature is simply meant to help guide you in specifying valid outputs, and is not required nor does it have an impact on the configuration and application of the transform itself (outputs shown as invalid can still be applied).
Considerations when Implementing the Transform
This transform is an extremely powerful tool for cleaning your data, but there are certain limitations and risks to be aware of.
- The model does not produce 100% accuracy and therefore should not be used in production environments.
- English is the only supported language at this time and we therefore recommend restricting all usage to be in the English language in order to produce accurate output data.
- Processing time can be lengthy. This means that the preview table can take minutes to load, and the actual run time of the connector may be significantly longer when using the transform.