

Transform Options | Yext Hitchhikers Platform
This reference details the available data transform options.
Add Column
This transform will add a column to the given data set with repeating row values that you specify.
To do this you will enter a Name for the column you’d like to add, and the repeating value of that column.
The value entered will apply to all rows, so this is something that applies to everything in the data set you are looking to load into Yext.
Apply Template Fields
This transform allows you to apply fields and values from an entity template to columns of your connector.
To use this transform, you must already have at least one entity template in your account.
Choose the desired template from the dropdown. In the modal that appears, choose which fields to add and map each to a column header. By default, all fields from the entity template can be added and auto-mapped to a matching existing column header, or to a new column header to be created upon saving the transform. It is not required to apply all fields on the template.
Template field values are kept up to date and reflect the values of the template at the time the connector is run.
If new fields are added to the template after the transform has been configured, the field must be manually added to the template transform configuration in order to be included (it will not automatically be added and mapped).
Field Limitations
Some fields and other entity information that can be included in an entity template cannot be applied via a connector. This includes:
- Entity Relationships
- Folders
- Categories
- Linked Accounts
- ECLs
- Any field using the Rich Text v1 (Legacy Rich Text) field type
If you have Rich Text (v1) fields in use that you would like to include in an Apply Template Fields transform, learn more about migrating your Rich Text (v1) fields to Rich Text (v2) in this guide: Migrate Legacy Rich Text Fields and Field Types
Check Entity Existence
This transform will add a column to the given data set that designates whether each row (entity) is new to the Knowledge Graph or already exists in the Knowledge Graph.
The transform checks against the Entity ID to determine whether or not the entity exists, and returns a value of true for existing entities, and false for entities that do not exist.
To use this transform, the user must specify which column in the data set contains the Entity ID for the transform to reference, and must provide a name for the new column containing the true/false values that will be appended to the data set (e.g., “Entity Already Exists”).
Convert to Rich Text
Use this transform to convert HTML or markdown data into AST JSON format.
To use this transform, select which columns in the data set to convert to Rich Text format, or click the toggle to convert All Columns. Then, choose the current format of the data set (HTML or Markdown) from the dropdown.
Duplicate Column
Use this transform to create a duplicate column with the same set of data.
To do this, select the column you would like to duplicate using the Input Column drop-down. Then, enter a Name for your new column header.
This transform might be useful when data needs to be mapped to two different fields on an entity. Or, when you have data that maps to a field in the Knowledge Graph, and also contributes to the value of another field that needs to be created via Transforms. You can use this transform to preserve the original value, and then manipulate the data in the duplicated column.
Extract Text
This transform will extract text from a column based on matching characters or offset. To do this you will enter the name of the new column for the extracted data. Then you will select the operation:
- All Text After
- All Text Before
- Some Text After (find a subset of text)
- Some Text Before (find a subset of text)
Next you enter the desired ‘Extract From’ setting — this specifies where the text should be extracted:
- First Instance of Matching Text: Delimit on the first instance of the matching text
- Last Instance of Match Text: Delimit on the last instance of the matching text
- Offset From Beginning: Determines the delimiter based on the provided Offset Length starting from the beginning of the text
- Offset From End: Determines the delimiter based on the provided Offset Length starting from the end of the text
Finally, enter the Matching Text, which is the text to search for that will queue the extraction.
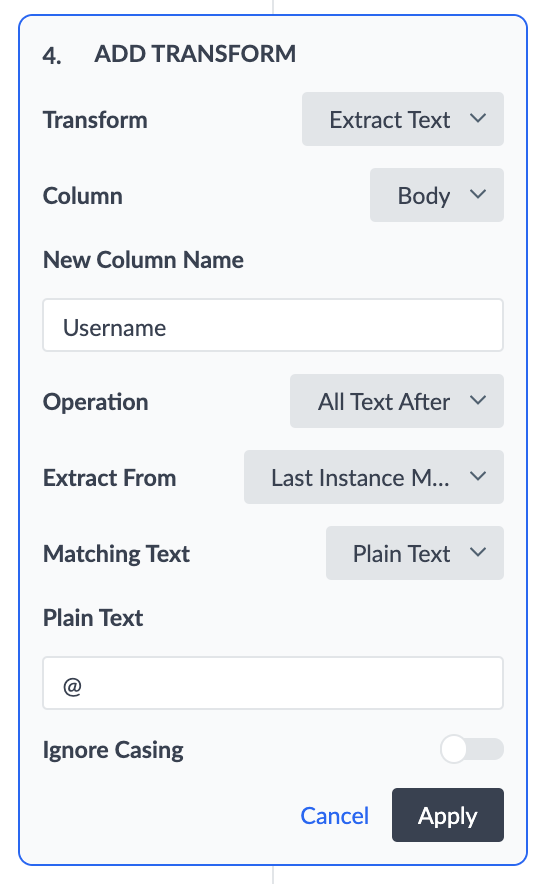
For example, you may want to extract usernames from a list of emails. To do this you can use the ‘All Text Before’ Operation where the ‘Extract From’ setting is the ‘First Instance of Match Text’, and the matching text is ‘@’.
| Name | Username | |
|---|---|---|
| Marty Morris | mmorris@turtleheadtacos.com | mmorris |
This would add the new ‘Username’ column above to your dataset.
Or, you may want to extract store IDs from a relative URL path. The URL path is consistent for each store, therefore they should use the offset option where the Extract Option is ‘All Text After’ and your Extract From setting is ‘Offset from Beginning’ and the Offset Length is 20.
| Name | Address | Relative URL | Store ID |
|---|---|---|---|
| Turtlehead Tacos | 123 Main Street | /turtleheadtacos/ca/store12 | store12 |
This would add the new ‘Store ID’ column to your above dataset.
Find and Replace
There are two find-and-replace transform options: use Find and Replace to replace all instances of one or more text strings with one replacement text string, or use Multi-Find and Replace to add more than one find-and-replace operation in a single transform.
Both types of Find and Replace transforms can accept multiple “Find” rules. However, only Multi-Find and Replace accepts multiple “Replace” rules.
“Find” rules can specify plain text and/or regex patterns. Pre-built regex patterns are also available to help employ commonly used regex patterns (e.g., the entire string, the beginning of a string, and the end of a string).
Considerations for both types of Find and Replace transforms:
- Blank cells: If the “Find” value is left blank, the transform will replace any empty cells with the “Replace” value. If the “Replace” value is left blank, any instances of the “Find” value will be replaced with a blank cell.
- Spaces: Trailing and leading spaces will be trimmed from both the “Find” and “Replace” values.
- Casing: Casing is ignored by default. If you would like the transform to be case-sensitive, you can toggle this on.
- Special characters: “Replace” values are treated as a literal string by default. You can choose whether to treat
$and/as special characters. If you do so, these characters will be executed according to the Java Replace function.
Find and Replace
Replace all instances of one or more text strings with one specific value that you provide.
You can specify multiple “Find” rules in a single transform. If there are multiple “Find” rules, they will be “OR” joined and executed in the following order:
- All plain text rules
- If there are multiple plain text rules, they will be executed in order of longest to shortest string.
- All regex rules
- If there are multiple regex rules, they will be executed in the order in which they are listed in the “OR” statements (i.e., the order in which they are provided).
Each row can only match one rule, and can only be replaced once. For example, if the following two rules are added:
- FIND:
I love cats. - FIND:
I love cats. I love dogs. - REPLACE:
I love frogs.
If the following input string is found: I love cats. I love dogs. I love all animals!, the second rule above will be found as a match (since it is longer), resulting in a final value of: I love frogs. I love all animals!.
Multi-Find and Replace
Execute multiple find-and-replace operations in a single transform. You can specify an “input” column and specify any number of find-and-replace operations.
As with the regular Find and Replace transform, you can specify multiple “Find” rules for a single “Replace” value. They will be executed according to the same rules:
- All plain text rules
- If there are multiple plain text rules, they will be executed in order of longest to shortest string.
- All regex rules
- If there are multiple regex rules, they will be executed in the order in which they are listed in the “OR” statements (i.e., the order in which they are provided).
Other considerations:
- “Find” rules cannot be repeated across multiple find-and-replace operations.
- Each value specified in a “Find” rule can only be replaced once.
Limitations
- Up to 500 key-value (find and replace) pairs per find-and-replace operation
- Up to 100 characters per key and value
Fix Capitalization
This transform converts the text of the inputted columns by applying the selected capitalization options:
- All Caps
- All Lower Case
- Proper Case
- This capitalizes the first letter of every word (e.g., This Is Proper Case)
- Proper case does not recognize words separated by hyphens as separate words, and will not capitalize them. For example,
galaxy grill to-gowould be formatted toGalaxy Grill To-go, notTo-Go.
Fill in Empty Cells
This transform will fill in a value for any cell where a blank is present.
First, select the column (or columns) for which to apply the transform. You can optionally select “All Columns”, which will also automatically apply the transform to any new columns added in the future.
Next, specify the value to apply to your data set. This value can be static, or it can include a column header to embed as the content.
Anywhere an empty cell is present in the specified column(s), it will be replaced by the specified value.
Filter Rows
This transform allows you to remove or keep rows based on a filter criteria provided. For example, the criteria can be one of the following:
- is blank
- is not blank
- equals
- does not equal
- contains
- does not contain
- greater than
- greater than or equal to
- less than
- less than or equal to
For example, if you want to upload product data, but you don’t want to upload any inventory that is out of stock you can use this transform to remove data that matches the criteria of ‘In Stock’ equals ‘No’. This would only upload the first two rows from the dataset below:
| Product Name | In Stock | Product SKU |
|---|---|---|
| T-shirt | Yes | 123456 |
| Tank top | Yes | |
| Sweatpants | No | 4567890 |
When using the ‘Filter Rows Based on Criteria’ transform, you can apply multiple criteria. You can select either AND conditionals, or OR conditionals. All criteria provided must use the same conditional (e.g., either all AND, or all OR). If you are only specifying a single filter criteria, the conditional you select will not have an impact on the final result, even though a selection is still required.
Meaning, you can exclude products that are both out of stock, and do not have an associated product SKU. Or, you can exclude any products that are either out of stock or missing a product SKU.
Format Dates
Use this transform to convert the format of your input date value into the format compatible with the Knowledge Graph.
First, select the column(s) to transform.
Then, choose whether to auto-detect the input date format. If you use the auto-detect functionality, then the system will attempt to match each value in each row to a format.
The benefits to auto-detecting the date format are:
- The input format of each value does not have to be the same. This means that a single transform can be used to clean multiple columns and/or rows that have varying data formats.
- You do not need to know how to write a format using the Java DateTimeFormatter notation.
However, if your format is extremely custom and the system is not able to successfully auto-detect the format, you will need to manually specify the format. To do this, select the date format that matches the input dates. If none of the options match, select “Custom” and enter a java.time.format.DateTimeFormatter compatible format string.
The transform will convert all inputs into the Knowledge Graph date format. That way, when mapping to a date field type, your date format will be valid.
For example, if your input dates are of the format 29-09-2022, using the auto-detect functionality, or selecting dd-MM-yyyy, will convert all dates into the Yext-compatible format: yyyy-MM-dd, or 2022-09-29.
Format Times
Use this transform to convert the format of your input time value into the format compatible with the Knowledge Graph.
First, select the column(s) to transform.
Then, choose whether to auto-detect the input time format. If you use the auto-detect functionality, then the system will attempt to match each value in each row to a format.
The benefits to auto-detecting the time format are:
- The input format of each value does not have to be the same. This means that a single transform can be used to clean multiple columns and/or rows that have varying data formats.
- You do not need to know how to write a format using the Java DateTimeFormatter notation.
However, if your format is extremely custom and the system is not able to successfully auto-detect the format, you will need to manually specify the format. To do this, select the date format that matches the input times. If none of the options match, select “Custom” and enter a java.time.format.DateTimeFormatter compatible format string.
The transform will convert all inputs into the Knowledge Graph time format. That way, when mapping to a time field type, your time format will be valid.
For example, if your input times are of the format 9:01:09 PM, select h:mm:ss a, and the transform will convert all times into the Yext-compatible format.
Function on a Row
The Function on a Row transform allows you to invoke fully custom Typescript functions to manipulate data in the Connector.
Function on a Row Transforms provide utmost flexibility in that they can accept multiple columns as inputs, and return outputs to multiple columns, for a given row in the Connector. This transform is especially useful for the the following use cases:
- Additional data (for each row) needs to be fetched from an API call and appended to the row as multiple new columns
- The output value of a column depends on the value of multiple input columns
Function on a Row Transforms expect a single object as the input data type, and an array of objects (with a maximum of 5 objects), or a single object as the output.
If the output type returned does NOT match that of one of the supported types, the Transform will fail to execute.
Input
| Type | Object |
|---|---|
| Example Function Definition | myObject: {id: string, name: string} |
| Example JSON | {id: “123”, name: “john”} |
| Behavior | The data from columns mapped to input keys will be used to construct the argument JSON |
Output
| Type | Object | Array of Objects | Undefined |
|---|---|---|---|
| Example Function Definition | Promise<{description: string, date: number}> | Promise<{description: string, date: number}[]> | undefined |
| Example JSON | {id: “123”, name: “john”} | {description: “Connectors help you manipulate data”, date: 01/01/2023} | |
| Behavior | The output object represents a single row of data, which will replace the existing row in the table for each execution | The output object represents a list of rows, whereby the first item will replace the existing row in the table for each execution. If the array is empty, the existing row will be removed from the table. |
A blank response will remove the existing row from the table. |
So, your function might look like the following:
export function myCustomTransform(rowObject: {inputCol1: string, inputCol2: string, inputCol3: string}) : Promise<object[]> {
/** TODO: write transform logic */
return
[
{outputColName1: string1, outputColName2: string2},
{outputColName1: string1, outputColName2: string2}
];
}To learn more about Function Development with Yext, check out our Get Started with Yext Functions guide.
The Connector will make a separate function call for each row in the Table. Based on your transform’s configuration, the system will construct the input object and parse the output for each function invocation.
First, you’ll need to specify the Plugin and Function that the transform should invoke.
You’ll then need to map the data in the Connector to the function’s inputs and outputs. Specifically, a Column Header in the Connector can be mapped to a “key” in your function. Essentially, your typescript function should be written to expect a structured object. The purpose of this mapping process is so that the system can correctly construct an object using the Connector data to match the structure the function expects as an input.
Inputs
Map each input key in the function to a Column Header in the Connector. The value for that key (that the function is invoked on) will be the value in the input Column Header for each row.
- Input Keys cannot be repeated and should not contain special characters nor spaces
- If an input key in your function is NOT mapped to any Column Header, it’s value will be sent as “undefined”
- If an input key is provided that does not match that of an input key in your function, the function will likely produce an error (or however the function is written to respond to an invalid input)
Outputs
Map each output key in the function to a Column Header in the Connector. The value returned for each key will populate the value of that column for the given row. Output values can overwrite the data in an existing column (i.e by mapping to an existing Column Header) or can populate an entirely new column by clicking to “+Add Column”.
- If an output key is specified in the config but is NOT actually returned from the function, the data in the column of the specified Column Header will be cleared.
Clear Column Values Setting (Default = FALSE)
By default, any Column Headers that are not specified as an output key will be preserved. This means that the function’s output is NOT considered comprehensive row data.
- If new rows are created from the function invocation, the new rows will have data in all other columns populated
Optionally, you can toggle this setting to TRUE, which means that any columns not mapped to an output key will be removed from the table. Setting this toggle to “TRUE” would be useful in the case where the output of the function is expected to be comprehensive row data.
Connector Limitations:
- We will only allow each function invocation to last 10 seconds. After 10 seconds, the given row will result in an ETL diagnostic.
- A maximum of 5 rows (5 items in the output array) can be generated and returned by a single function invocation. If more than 5 items are returned, an ETL diagnostic will occur for the given input row.
As a reminder, ETL diagnostics details available in the etl_diagnostics.csv file). These errors result in the input row being dropped from the run if in Default Mode, or in the entire run failing if run in Comprehensive Mode (see more information about Run Modes here)
Example
I have rows of data that each contain data for a movie. I want to use a function to get the data for the top 3 actors of for each movie, and create rows for each actor. The end goal is to create actor entities
Original Table (This is a Single Row → the Function would execute the same way on EACH ROW)
| Full Name of Movie | Release Month | Entity ID |
|---|---|---|
| Step Brothers | July | 123 |
Final Table (Clear Column Values = TRUE)
| Full Name of Movie | Entity ID | Release Month | Actor Name | Actor ID | Color |
|---|---|---|---|---|---|
| 123 | Will Ferrell | 123 | Blue | ||
| 123 | John C. Reilly | 321 | Red | ||
| 123 | Adam Scott | 111 | Orange |
Final Table (Clear Column Values = FALSE, default)
| Full Name of Movie | Entity ID | Release Month | Actor Name | Actor ID | Color |
|---|---|---|---|---|---|
| Step Brothers | 123 | Will Ferrell | 123 | Blue | |
| Step Brothers | 123 | John C. Reilly | 321 | Red | |
| Step Brothers | 123 | Adam Scott | 111 | Orange |
Function
export async function getActors( movie :
{name: string, id: string}
) : Promise<object[]> {
/** For the Movie name and ID, fetch the data for the top 3 actors
Construct an Array of objects, where each object is the data for an actor
Return the Actor Data and Movie ID, do not return the Movie Name
*/
return
[
{name: name, id: id, actorName: generatedActorName1, actorId:
generatedActorId1, color: generatedActorFavColor1},
{name: name, id: id, actorName: generatedActorName2, actorId:
generatedActorId2, color: generatedActorFavColor2},
{name: name, id: id, actorName: generatedActorName3, actorId:
generatedActorId3, color: generatedActorFavColor3},
]
}Transform Configuration to Achieve the Final Result
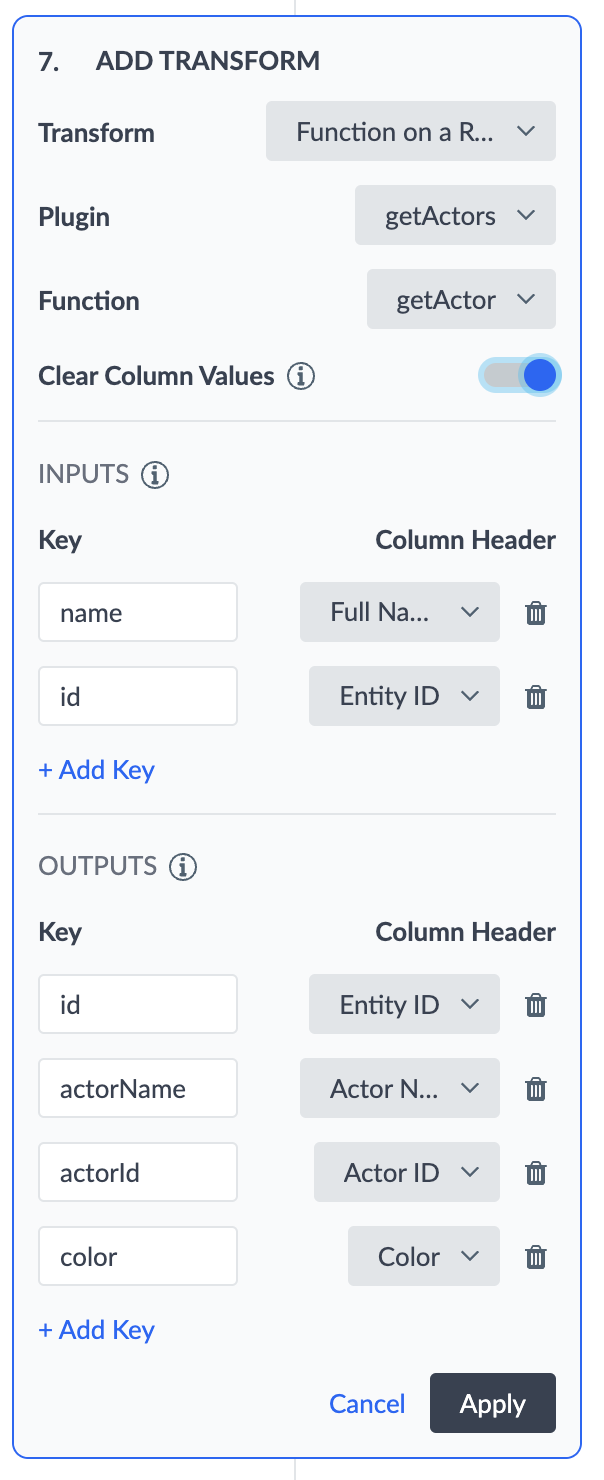
Input Mapping Code Representation
[{“functionKey”: “name”, “columnHeader”: “Full Name”}, {“functionKey”: “id”, “columnHeader”: “Entity ID”}]
Output Mapping Code Representation
[{“functionKey”: “id”, “columnHeader”: “Entity ID”}, {“functionKey”: “actorName”, “columnHeader”: “Actor Name”}, {“functionKey”: “actorId”, “columnHeader”: “Actor ID”}, {“functionKey”: “color”, “columnHeader”: “Color}]
JSON Data Constructed to be sent in a Single Invocation (as per the Provided Configuration)
Input:
{“name”: “Step Brothers”, “id”: “123”}
Output:
[
{id: “123”, actorName: “Will Ferrell”, actorId: “123”, color: “blue”},
{id: “123”, actorName: “John C. Reilly”, actorId: “321”, color: “red”},
{id: “123”, actorName: “Adam Scott”, actorId: “111”, color: “orange”}
]Function on a Single Cell
Functions are custom transforms. You can create a fully customized Function in TypeScript.
Function on a Cell Transforms will expect a single generic function signature, outlined below in TypeScript.
export function myCustomTransform(cellValue: string): string {
/** TODO: build transformed cell */
return cell;
}When creating a Function on a Cell Transform, you must specify which Columns in the Table that you would like to transform. The Connector system will make a separate function call for each Cell in each specified Column in the Table, hence the singular string argument and expected return value.
After creating a custom function, you can then select the function in the Transform UI as you would select a built-in transform.
To learn more about creating functions visit the Get Started with Yext Functions guide.
Get Entity Field Data
Use this transform to extract existing field data from entities. Specify the field(s) to fetch for the given entity IDs, and then specify the destination for that data.
Specify these options in the connector settings:
- Specify the column containing the Entity IDs you want to fetch field data for. This column can also contain linked entity IDs.
- If using multi-language profiles, select a column containing the locale code for the entity profiles you want to fetch data for. Otherwise, leave blank to use the default entity profile.
- Select one or more fields to fetch data for, and where that data should be output to.
Formatting for data returned from fetched fields is below:
| Field or Data Type Fetched | Returned Data Format |
|---|---|
| Option fields | API name of field and options |
| List fields | Comma-separated list |
| Rich Text fields | JSON Abstract Syntax Tree (AST) |
| Entity Relationship fields | Entity ID |
| Entity labels | Display name of label |
| Entity folders | Folder path |
Limitations
- Getting data from the following fields and field types is not supported:
- Categories
- Google Attributes
- Linked Accounts
- Struct fields
- List of struct fields
- Photo fields
- Video fields
- Maximum fields to fetch per transform: 50
Ignore Columns
Use this transform to remove specified columns from the preview table. This will filter your view so that only relevant columns are visible in the UI and available to be used in subsequent transforms and mapped to a field in the Knowledge Graph.
Map Publisher Categories
Use this transform to set the Yext Category ID for entities created by pulling data from Google Business Profile.
When fetching location data from Google Business Profile to create entities in Yext, the Google API will return the Google category IDs for your locations. In order to create location entities in Yext, those Google category IDs must be mapped to the corresponding Yext Category IDs.
Select the column (or columns) to apply the transform, or select “All Columns” to automatically apply the transform to any new columns added in the future. The transform will return the mapped Yext category IDs.
If your cells contain lists of category IDs, the transform will ingest the entire list and return the transformed list.
Merge Columns
This transform will merge columns together with an optional delimiter. To do this, you select the columns you want to merge from the drop-down menu. The order of the columns you select will determine the order of the merged data.
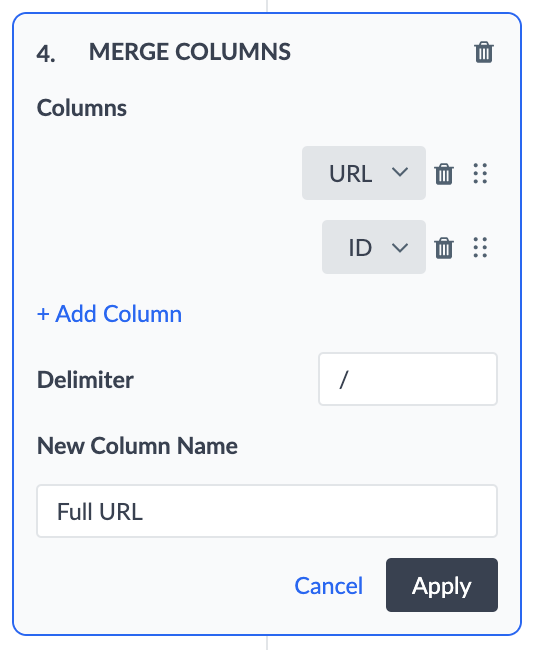
For example, if you have a column with the URLs from the main domain of your page, and you have a separate column for your Store IDs, you can merge the columns to create the store specific URLs.
To do this, you would merge the URL column with the Store ID column, and use ‘/’ as the delimiter. This would add ‘Full URL’ as a new column to the below dataset.
| Location Name | URL | Store ID | Store ID |
|---|---|---|---|
| Turtlehead Tacos | https://turtleheadtacos.com |
store12 | https://turtleheadtacos.com/store12 |
Normalize Address
Use this transform to format data into the proper Address fields ingestible by the Knowledge Graph. This transform handles three main use cases:
Split address information contained in a single string into its respective fields (e.g.,
61 9th Ave, New York, NY 10011is split into the below subfields):- Address Line 1: 61 9th Ave
- City: New York
- State/Region: NY
- Postal Code: 10011
- Country: US
Fill in missing fields for a partial address (contained in multiple columns for the respective address fields). E.g., given an Address Line 1 value of
61 9th Aveand a City value ofNew York, the transform will fill in the following subfields:- State/Region: NY
- Postal Code: 11205
- Country: US
Populate Address fields (Address Line 1, City, State/Region, Postal Code, Country) given a latitude/longitude pair mapped to the Display Coordinate (
displayCoordinate) field.
Remove Characters
This transform trims spaces and removes all unwanted special characters, numbers or spaces from the inputted columns of data.
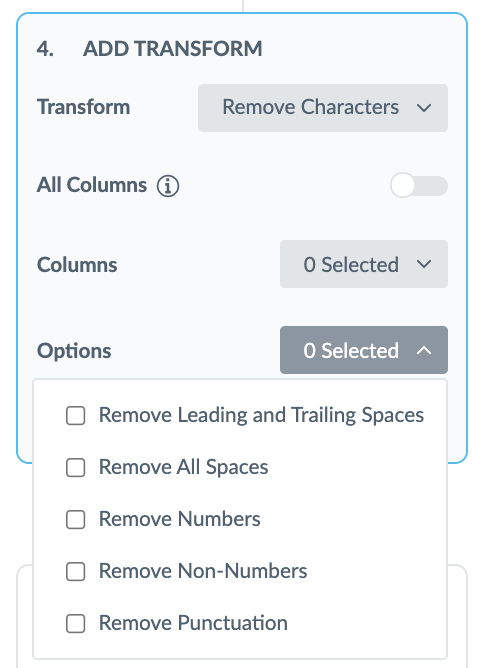
For example, if the data you pulled in from your Connector looks like the example below, you can apply the ‘Remove Unwanted Characters’ transform to the Year Established Column to remove the slash.
| Location Name | Year Established |
|---|---|
| Turtlehead Tacos | /2013 |
| Turtlehead Tacos | /2005 |
| Turtlehead Tacos | /2014 |
Split Column
This transform will split the selected column into new, distinct columns at each occurrence of a specified delimiter.
First, specify the input column you would like to split. Next, add a Name for each new column you’d like to create. Finally, you’ll need to specify the delimiter by which to split your column.
Note that the transform will not make any changes to your input column value, rather, it will only create new columns. So, if you only specify one New Column, that column will always retain the exact value of the existing column, since two columns into which to split the data were not provided.
For each new column you’ve specified, the transform will look for the first occurrence of the delimiter, where it will then remove the delimiter and split the column into two separate columns.
If you have specified fewer new columns than the number of occurrences of the delimiter, the column will not split at any subsequent occurrences.
If you have specified more new columns than the number occurrences of the delimiter, the new columns will be created but will contain blank values.
As an example, let’s say a restaurant has pulled in a list of all their menu items. The data source has them populated as a single column (with all Menu Items), but you would like to create distinct fields on your entity for each item type, namely for Drinks, Breakfast, and Lunch items.
To do so, you can use the Split Column Transform with the following settings:
- Column: Menu Items
- New Columns:
- Drinks
- Breakfast
- Lunch
- Delimiter:
/
This would result in the following transformation. (Notice how the delimiter, /, occurs twice, and three new columns must be specified to achieve the desired result).
Original Data:
| Name | Address | Menu Items |
|---|---|---|
| Turtlehead Tacos | 123 Main Street | coffee, tea, orange juice/breakfast burrito, pancakes, eggs/tacos, taco salad, combo platter |
Transformed Data:
| Name | Address | Menu Items | Drinks | Breakfast | Lunch |
|---|---|---|---|---|---|
| Turtlehead Tacos | 123 Main Street | coffee, tea, orange juice/breakfast burrito, pancakes, eggs/tacos, taco salad, combo platter | coffee, tea, orange juice | breakfast burrito, pancakes, eggs | tacos, taco salad, combo platter |
Split Into Rows
Use this transform to split your column into one or more rows, based on a specified delimiter (such as a comma).
You’ll need to select the column(s) containing the data that needs to be split and specify the delimiter.
Once applied, all occurrences of the delimiter will be removed and the row will be split at each occurrence. All other columns will repeat the same data values for each new row that is created.
If multiple columns are selected, the final number of rows (for each starting row) will be based on whichever column has the most occurrences of the delimiter. For any columns that are part of the split and have fewer occurrences of the delimiter, cells in those columns will be blank for the remaining rows.
For example, say a healthcare client manages their doctors, associated specialities, and associated hospitals via an Excel sheet, where doctors and specialties are stored in a single row for each hospital. To create doctor entities for all of doctors, the Split Column transform can split the “Doctor” and “Specialty” columns into rows, where the delimiter is a comma. All other column data remains unchanged.
Data before transform:
| Doctor | Hospital | Specialty |
|---|---|---|
| Dr. Cutler, Dr. Smith, Dr. Finjap | MGH | Cardiology |
| Dr. Joe, Dr. Sally, Dr. Bob | Brigham and Women | Emergency |
Data After Split into Rows Transform:
| Doctor | Hospital | Specialty |
|---|---|---|
| Dr. Cutler | MGH | Cardiology |
| Dr. Smith | MGH | Cardiology |
| Dr. Finjap | MGH | Cardiology |
| Dr. Joe | Brigham and Women | Emergency |
| Dr. Sally | Brigham and Women | Emergency |
| Dr. Bob | Brigham and Women | Emergency |